| 3.0 Introduction |
Module 3 Exercises
- Write regular expressions for:
- Real numbers that include those represented by the following examples: 0.3, 3.0, 1.52, 0.5E-1
- Identifiers that begin and end with $ and have any number of letters, digits, and $ in between.
- Relational operators as expressed in:
- C: ==, !=, <, <=, >, >=
- Pascal: <,>, =,<>, <=, >=
- FORTRAN: .LT., .GT., >EQ., .NE., .LE., .GE.
- Ada: =, /=, <, <=, >, >=
- A language of your choice
- The driver algorithm in Section 3.2 is missing many details. For example, the issue of blanks needs to be addressed. Extend the algorithm to ignore blanks and to:
- Use blanks as a delimiter within the strings, that is, finding a blank denotes the end of the current token.
- Allow blanks within tokens, that is, Max1 is the same token as Max 1.
- Example 3 shows a partial table for recognizing an identifier consisting of letters and digits beginning with a letter. Since neither letter nor digit is a single character, more details need to be provided. Traditionally there have been two methods. Discuss what these might be (and then check the answers to selected exercises).
- Show a CASE statement equivalent to the table in Example 3.
- Write the details of the four actions GetChar, Accept, Retract, and Return from Section 2.
- From the method described in Section 3.3.1 write an algorithm to convert from an from a regular expression to a NFA. Describe the NFA as an abstract data type, rather than deciding upon a particular implementation such as a table or CASE statement.
- Using the method described in step 2 of Section 3.3.2 , write an algorithm to convert from an NFA to a DFA, again describing each of the NFA's as an abstract data type.
- Using the method described in step 2 of Section 3.3.3 , write an algorthm to convert from DFA to a minimal DFA, again describing each of the DFA's as an abstract data type.
- Implement an NFA (as described in Exercises 6 and 7) as (a) a table and (b) a CASE statement.
- Name some applications where it would be better to do the extensive work required to write a lexical analyzer generator, rather that writing a lexical analyzer and then making changes to it when needed.
- Is the LEX grammar unstratified? You will need a LEX manual to answer this.
- The table in Section 3.3.1 1 step (d) is incomplete. Add the missing information.
- Convert the following to a DFA.
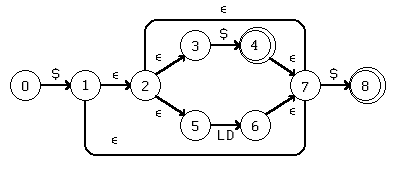
- Convert the following to a minimal DFA.
a |
b |
|
>A |
B |
A,D,F |
B |
|
C,F |
C |
A |
G,D |
D |
E |
E,D,H |
E |
|
F |
*F |
|
D,H |
G |
B |
G,D,H |
*H |
|
|
![]()