Hardware Acceleration for Window Systems
a summary by Markus Altmann
based on the paper of D. Roden & C. Wilcox
Introduction
Window systems are workstation-user interfaces for creating & manipulating
windows, corresponding to the screen area of a process. It provides
the user with simultaneous access to multiple processes on the
workstation and enables him to manage more tasks at a time, increasing
productivity. Since each process associated with a window, views the
workstation resources (CPU, memory, graphics HW) as if it were its
sole owner, the resources must be shared with no conflicts, to finally
preserve interactivity.
Sharing the graphics HW to provide a virtual graphics device to each
process requesting graphics, requires extensive HW support within the
graphics system. The problem with the virtual implementation results
from the pipeline architecture of the graphics devices, causing
pipeline latency. This results from pipeline flushing &
resynchronization for context switching/swapping when sharing a
graphics accelerator. These are costly operations and impact the
responsiveness and user interactivity of the graphics system. The
problem increases with more complex primitives, e.g. splines, in the
pipeline, causing more processing time and increases the pipeline
length; pipeline flushing is then even more expensive.
Therefore, an alternative to pipeline flushing is necessary. Since SW
solutions are not fast enough, HW solutions are required to provide
interactivity with a significant (but limited) number of windows,
especially those requiring the graphics accelerator. The graphics
devices must be shared in an effective manner and the influence of
graphic operations within one window on others should be
minimal. Moreover, the need for pipeline flushing and
resynchronization must be eliminated. To support the window system,
the following HW components are integrated at correct locations in the
pipeline, to minimize the interaction between the window system SW and
graphics rendering (Fig. 1).
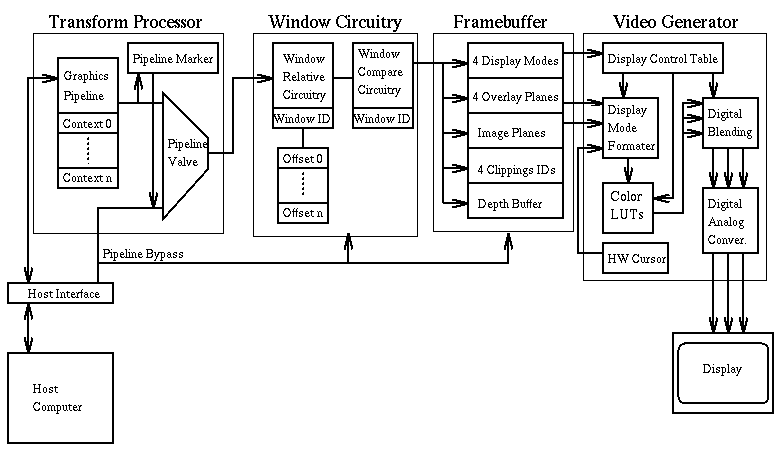
Fig. 1: Scheme of the HW components of the window acceleration system.
The Transformation Processor
The transform processor block is implemented with parallel floating
point processors and is the core of the accelerated graphics
system. These processors perform tasks such as graphics context
management (HW state information, e.g. matrix stack, light sources,
etc. ), matrix transformation calculations etc. and include the
following HW resources for acceleration purposes.
Multiple Graphics Contexts
The graphics contexts are stored in HW, eliminating the constant
context passing between host and graphics device, allowing efficient
context switching without pipeline flushing and simultaneous rendering
in multiple windows. The number of contexts to store is limited by
memory size associated with the transform processor. When all HW
contexts are allocated, software context switching can swap out the
least recently used context.
Pipeline Synchronization
Pipeline synchronization assures the requested order of rendered
primitives from competing processes. The synchronization HW divides up
primitives and hands them to individual transform processors. When this
happens, a sequence marker is stored in the sequence manager circuit,
to maintain the order of the primitives, so order dependent results will be
consistent & repeatable.
Pipeline Bypass
The pipeline bypass is a separate path for window primitives (buttons,
window frame, etc.) not requiring the pipeline to allow the window
system direct access to the framebuffer. The bypass supports block
move/read/write operations in HW (see later in Window Circuitry) and
can be used for direct rendering of window system primitives. It
avoids overhead of the graphics pipeline, while providing relatively
simple operations of the window system, which finally results in good
window system interaction, even in the middle of complex rendering
operations.
Pipeline Valve
Since the framebuffer can also be accessed by the pipeline bypass, the
pipeline valve controls this access. The pipeline valve turns off the
data from the rendering HW, so the window system can access the
framebuffer for window manipulations without regarding the pipeline
context. This does not stop the transformation processors, so primitive
processing continues until the pipeline backs up. After the window
manipulation and once the valve is open for the rendering HW, the
primitives will be rendered at the correct screen location.
Pipeline Marker Circuitry
With this circuitry the window system SW can ensure, that all
primitives of the context being swapped out are rendered before
swapping. This prevents unnecessary pipeline flushing when changing
contexts, which is required because of limited resources, shared
between multiple processes. The pipeline marker is a register,
accessed by the window system via the pipeline bypass without closing
the valve. This register is updated when a marker, which is incremented and
sent between context switches in pipeline, reaches the pipeline end. A
table of the active contexts currently in pipeline associated with a
marker is maintained. Therefore, on a context switch, the window
system can determine the contexts in the pipeline by reading the
register and referring to the table of contexts. If the context being
swapped out is not in the pipeline, then the context switch can occur
immediately, otherwise the window system has to wait for processing
this context. However, it is at no time necessary to stop the pipeline
or prevent processes from placing commands & data into the pipeline.
Window Circuitry
The following window HW has its logical location between the rendering
HW and framebuffer, to eliminate the need for pipeline flushing.
Window Relative Rendering
This allows a graphics application to treat the window as a full
screen virtual device, so it does not need to be window smart, which would
reduce overall system performance by adding window offsets and
clipping to window boundaries. All primitives in the pipeline are
specified relative to the window origin and translated to screen
relative coordinates after scan conversion. The offset for each window
is maintained in a table in the window relative circuit, which can be
asynchronously updated via pipeline bypass and closing the pipeline
valve while moving or shuffling the windows. After the valve is
opened, rendering will proceed correctly at new location, so window
translations are completely transparent to applications, not knowing
their window location. This happens with no loss of performance, since
the window offset is performed in parallel with pipeline
operations.
Window Block Mover
Block move operations support basic window primitives, e.g. raster
text, icons, window move/shuffle/resize, etc., and are important for
window system performance. In order to perform these operations window
as well as screen relative, a register is used, with a bit for each
operand, indicating the coordinate system to use. This allows
offscreen objects, like raster text, to be moved into a window without
offset calculation, which is done by the window relative HW. The
application is not required to decide about the coordinate system,
which avoids extra processing by the window system of the
application. If an object is offscreen, then the operation is screen
relative; if the object is displayed, it is window relative, otherwise
an explicit command determines the way of operation.
Window Burst Transfer
With this feature large amount of pixel data can be moved to and from
system memory for screen redraw, save/restore operations, which occur
quickly with acceleration, reducing the need for optimizing
fonts/bitmaps in offscreen memory. The HW ensures the transfer of the data
to the right display location and allows an additional offset to
transfer not aligned data in system memory without loss of
performance.
Window Compare Circuitry
The compare circuit supports HW clipping of pixels to arbitrary
boundaries in real time, reducing window system interaction with
applications. A window id is written to the circuit for all following
pixels to be drawn. Each pixel is then compared with the window id in
the clipping planes of the framebuffer at the pixel position in order
to clip the pixel or not. This allows efficient clipping even while
complicated objects are rendered in a window environment.
Framebuffer
Beside the memory holding indices to specific colors, extra
framebuffer planes are added to allow high speed window clipping and
multiple display modes.
Window Clipping Planes
This clipping planes contain id's for the windows currently controlling
each pixel. The window id of a pixel to be drawn is compared with the
window id stored in these planes by the window compare circuitry. If
both id's are equal, then the pixel is inside the window and is drawn,
otherwise it is discarded and clipped.
Window Display Mode Planes
Similar to the previous planes, each window id coded in the window
display mode planes is associated with a display mode (e.g. 8 bit
planes, 24 bit planes, 12 bit plane double buffer) to allow different
display modes in different windows at a time. According to these
modes, the display processor of the video generator reformats the data
in the framebuffer to display the mode for each pixel.
Window Overlay Planes
Overlay planes allow windows to coexist with rendered images by
merging these planes in front of the image planes. The actual contents
of the images planes are not destroyed by the overlay data, so
rendering to image windows occluded by overlay windows is possible.
Window Offscreen Planes
These planes are areas of the framebuffer not displayed and good for
raster fonts and texture. The objects stored in this area can be
copied with block move operations from framebuffer to framebuffer,
which is faster than from system memory to framebuffer.
Video Generator
The video circuitry formats framebuffer data according to the current
display mode, maps it through a color lookup table (LUT) and converts
the digital values to analog signals. The video generator provides the
following HW components for window support.
Multiple Display Modes
This component allows each window to define its own display mode by
determining the mode for each pixel of the windows according to the id
stored in the display mode planes of the framebuffer. The display mode
id is an index into the display mode table and also determines the
color LUT and other attributes, such as blending for each pixel.
Multiple Color Maps
As indicated in the previous paragraph, the id stored in the window
display mode planes is also an index into the HW color table, allowing
each window to have its own color map. However, there are restrictions
on types of different display modes in use at a time, because of
limited storage supply for color LUTs.
Hardware Cursor Support
The HW cursor shape is never stored in the frame buffer, because the
shape data is directly placed into the pixel stream before the
digital/analog conversion. This avoids the synchronization with the
framebuffer data as it is necessary with SW cursors when rendering
images, while moving the cursor. The only data to update the HW cursor
is its new location, therefore, providing good performance and
interactivity, since no additional updating tasks are required as
opposed to a SW cursor.
Conclusion
The presented HW support provides high performance, interactive window
handling, by placing this support at correct stages of the graphics
pipeline. This allows more complex primitives in the pipeline, while
preserving and even improving window operation performance.
Reference:
Roden, Desi & Wilcox Chris,
"Hardware Acceleration for Window Systems",
Computer Graphics, Vol. 23, No. 3, July 1989
![[Return to CS563 '95 talks list]](/images/back.gif)
Markus Altmann /
madwpi@cs.wpi.edu