CS 2223 Dec 08 2015
Expected reading:
Daily Exercise:
There are many shortcuts to failure, but there are no shortcuts to true success
Orrin Woodward
1 Weighted graphs
The final extension to the graph structure is assigning numeric weights to each edge. These weights represent various real-world measurements, such as distance, time, or cost.
1.1 Directed Weighted Edge
Associating a weight is nothing more than constructing a structure to keep track of the source and target vertices and the edge weight:
public class DirectedEdge { final int v; final int w; final double weight; public DirectedEdge(int v, int w, double weight) { this.v = v; this.w = w; this.weight = weight; } public int from() { return v; } // Tail vertex of edge public int to() { return w; } // Head vertex of edge public double weight() { return weight; } // Weight of edge /** String representation. */ public String toString() { return v + "->" + w + " " + String.format("%5.2f", vweight); } }
How does this change the landscape? Well, consider the following graph:
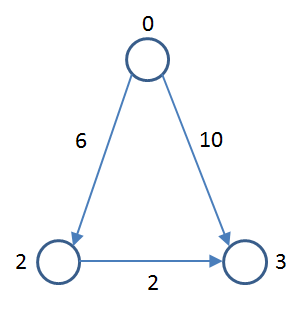
If you explore this graph using a Breadth First Strategy, you will see that you can get from vertex 0 to vertex 3 in one edge of weight 10, but if you traverse 0-2-3 over two edges, the accumulated length is 8 which is a shorter path.
We can’t use Depth First Search to find the shortest path. Using Breadth First Search would give the shortest path by total number of edges but not accumulated weight. Clearly we need some other strategy. Let’s be precise:
We want to compute the shortest possible accumulated path from a designated source vertex to each other vertex in G reachable from s.
We want to be able to recover these paths as needed.
To guide us in our search, reflect on a simple strategy that you used intuitively on the simple graph: Take action when your current shortest path calculation of s to t is larger than the sum of the distance from s to some vertex x plus the sum of the distance from x to t. To make this work you need to store extra information, but what should it be?
Consider how Breadth First Search constructed an array distTo[v] that recorded the shortest number of edges to traverse from vertex s to vertex v. In our case, use an array dist[v] that records our best computed shortest path from s to each vertex v. You can initialize this array to Infinity for all vertices, other than s which is set to 0.
This is half of the situation. However how can we find some vertex t which grants us a shorter path s-t-v for any vertex v? The answer is to be disciplined in our search.
We need only locate a vertex u that points to t, then we can check to see if dist[u] + weight(u,t) is smaller than dist[t].
Much like Breadth First Search, we will start at a known source vertex, and set its distance to 0 while all other vertices get a computed distance of Infinity. We now place all of these vertices into a Priority Queue that records the shortest known distance to s for any vertex. In our core functioning loop, we retrieve a vertex that has the shortest distance computed from s and we expand from that direction only.
This is directly analagous to the Breadth First Search strategy, this time using the measure of "distance from s" as a means of ordering the vertices in a priority queue.
Once done, the following core loop will serve our purposes. We find a vertex that has shortest distance and remove it from the priority queue and see if we can reduce the computed shortest distances for all of its outgoing adjacent vertices.
while (!pq.isEmpty()) { int v = pq.delMin(); for (DirectedEdge e : G.adj(v)) { relax(e); } }
The definition of relax is as follows, and follows the earlier intuition:
void relax(DirectedEdge e) { int v = e.from(); int w = e.to(); if (distTo[w] > distTo[v] + e.weight()) { distTo[w] = distTo[v] + e.weight(); edgeTo[w] = e; pq.decreaseKey(w, distTo[w]); } }
Now, with this priority queue implementation, we use a special structure known as an IndexMinHeap which takes a basic heap structure and adds a specific capability, namely:
Determine existing index in heap for given key
Allows you to decrease the priority for that key – essentially moving it closer to the front of the queue.
The details are found in the indexMinPQ class and are worth studying, but you need only know that they existy for this logic to work.
So now you have everything in place. Dijkstra’s algorithm methodically eliminates vertices from consideration one at a time (much like Breadth First Search does by marking vertices as they are encountered). In this case, however, they are "visited" in order of their shortest accumulated path from s. No longer do we mark vertices, but rather we maintain a priority queue of vertices that have yet to be visited. Once the priority queue is empty, we are done.
1.2 HW5 suggestions
1.2.1 Proof question
It is possible to answer the question without relying on proof by induction.
Consider the following: Can a Binary Search Tree contain a cycle? Can you prove it?
/** Insert key into BST. */ public void insert(Key key) { root = insert(root, key); } Node insert(Node parent, Key key) { if (parent == null) return new Node(key); int cmp = key.compareTo(parent.key); if (cmp <= 0) { parent.left = insert(parent.left, key); } else { parent.right = insert(parent.right, key); } return parent; }
Consider the following fact: when adding a new key to a binary search tree, the key is added to a new leaf node that is added to the tree. Because it is a leaf node, it has no left or right child, so it cannot be involved in a cycle.
Given a Binary Search Tree containing a single node (the root, which is also a leaf) there is no cycle. Adding a node to a BST does not create a cycle as stated earlier, thus any sequence of insertions will not create a cycle.
To complete this proof, you would need to consider the delete operation as well. While adding some additional complexity, the same argument should be used.
1.2.2 Single-Source Shortest path Dijkstra Matrix Implementation
The "Dijkstra’s Algorithm DG" specification in question 4 is typicaly of what you would find in textbooks when describing algorithms.
As such there is still some ambiguity! Recognizing this was part of the assignment.
Specifically, consider steps 5 and 6:
while (true) determine u whose dist[u] is smallest of unvisited vertices
Well, what if there are no unvisited vertices? Hah!
So you should interpret lines 5 and line 6
while some unvisited vertex v has dist[v] < INFINITY do determine u whose dist[u] is smallest of unvisited vertices
1.3 Version : 2014/03/04
(c) 2015, George Heineman