
12.3.13 Storage Allocation for Arrays
The previous sections have discussed storage allocation "in the large", that is , the general activation record mechanisms necessary to facilitate assignment of data to variables.
Here, we disucss one issue "in the small", that of computing the offset for an element in an array. Other data structures such as records can be dealt with similarly (see Exercise 1).
Computation of Array Offsets
Array references can be simple, such as
A[I]
or complex, such as
A[I - 2, C[U]]
In either case the variables can be used in an equation that can be set up (but not evaluated) at compile-time.
We will do this first for an array whose first element is assumed to be at A[1,1,1,...,1].
That is, given an array declaration
A: ARRAY [d1, d2, ... dk] OF some type
what is the address of
A[i1, i2, ... ik]?
It is easiest to think of this for the one- or two-dimensional case. For two dimensions, what is the offset for
A[i1,i2], given a declaration A: ARRAY[d1, d2] OF some type
By offset, we mean the distance from the base (beginning) of the array which we will call base (A).
To reach A[i1, i2] from base (A), one must traverse all the elements in rows 1 through i1 - 1 plus all the columns up to i2 in row i1. There are d2 elements in each of the i1 rows; thus, A[i1, i2]'s offset is:
(i1 - 1) * d2 + i2
The absolute address is
base (A) + (i1 - 1) * d2 + i2
For k-dimensions that address is:
base (A) + ((((i1 - 1) * d2 + (i2 - 1)) * d3 + (i3 - 1))
* d4 + ...) * dk + ik
or
base (A) + (i1 - 1) * d2d3...dk + (i2 - 1) * d3...dk + ...
+ (ik-1 - 1) * dk + ik
The second way is better for the optimization phase because the sum of indices is multiplied by constants, and these constants can be computed at compile time via constant computation and constant propagation.
In the next section, we discuss an implementation method using attribute grammars. This was touched upon in Module 6.
Computation of Array Offsets Using Attribute Grammars
Consider the following grammar for array references:
NameId Name
We want to be able to attach attributes and semantic functions to these.
Example 6 shows a three-dimensional example and attributes Dims, NDim and Offset. Dims is an inherited attribute. It consults the symbol table at the node for the array name (A here) and fetches the values d1, d2, and d3 which are stored there. These are handed down the tree and used in the computation of Offset, which is a synthesized attribute. Attribute NDim is a counter that counts the number of dimensions, presumably for error checking.
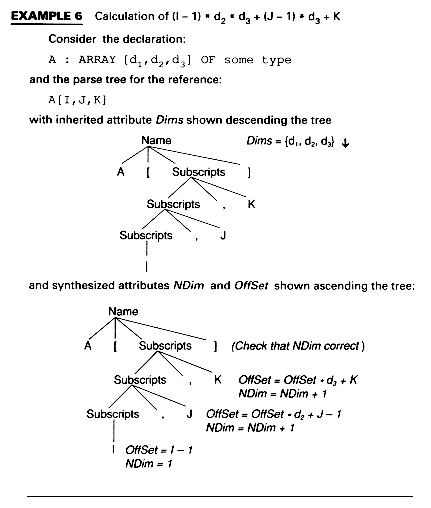
Exercise 3 asks the reader to write the semantic functions to compute the values for these attributes, while Exercise 4 suggests another way to write the grammar that will allow the attributes to be evaluated in one pass up the tree. This is material repeated from Module 6, so the reader may wish to refer back to that chapter.
The exercise ask the reader to consider other compile-time structures which have storage needs such as record.
In sections 12.5 and , 12.6 we describe a few compilers to see how a compiler in the real world has made the compromises described in this chapter (as well as other compromises).