[WPI] [cs2223] [cs2223 text] [News] [Syllabus] [Classes]
We made a few more comments about the divide and conquer technique for N-digit integer multiplication. The numbers need not bee the same size. Look at several cases:
This is the divide and conquer algorithm we we analyzed in Class 14. In that analysis, we showed that the algorithm we learned in grade school for multiplying two N-digit numbers is inherently of order O(N2).
We can split each number into two halves, each of size N/2, so we can use a divide and conquer technique. Four multiplies are required at each step. That produced a recurrence relations whose solution is still of order O(N2).
![]()
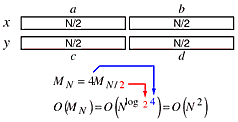
By rearranging the terms to reduce the number of multiplications to three, we also reduced the order of the algorithm.
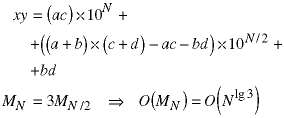
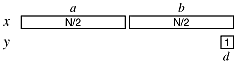
When one of the numbers is of length one, we are back to the case of grade-school multiplication. We can still use the divide and conquer algorithm to reduce this to a sequence of single-digit multiplications. Our analysis shows that it is linear in N.
![]()
When one of the numbers of one half the length of the other number, we can still find a recursive divide and conquer algorithm which is linear in N.
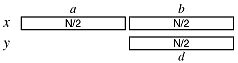
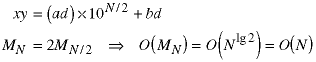
Thus we suspect we can use divide and conquer techniques to create an algorithm which is linear in N, the length of the longer number, when the shorter number has length between one and N/2 and which grows to order O(Nlg3) when when the shorter number has length between N/2 and N. Many commercial implementations of algorithms have this adaptive quality - different algorithms or sub-algorithms are used depending on the detailed characteristics of the data.
Can you devise a multiplication algorithm which works optimally for all possible integer lengths?
If the smaller number is smaller than N/2, just add enough leading zeros to make it of order N/2, for which we have shown a linear algorithm.
If the smaller number is larger than N/2, we can divide keep the division between the two halves at N/2. Then
Suppose the numbers are of different length, but both are even numbers. We can still use the usual divide and conquer analysis:
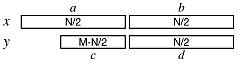
The lowest halves, b and d, remain the same size at each level of recursion. However, at some recursion level, the c portion will be of size 1 and then zero at the next level. So, at some point the algorithm has to switch from the O(Nlg3) algorithm to the O(N) algorithm. Think about how to detect when the change is necessary.
How about the case when N is neither odd nor a power of two? It is important that the two lowest halves be the same size (or we cannot combine the terms to reduce the number of multiplications from four to three). But, we can use this fact which works in integer math.
![]()
This is true in integer math for all integral values of N, both even and odd. Further, the second term on the left is always the same size as or larger than the first on the left. So, we can use these values to divide up the numbers into "halves".
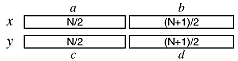
The parentheses have to be kept as shown. In integer math, these quantities are not necessarily the same (can you prove it?)
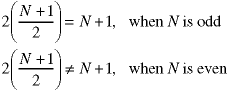
The proper analysis of this alrogithm requires the use of floor and ceiling functions. If you wish to learn more, look for a discrete mathematics or algorithms text which talks about the floor and ceiling functions. Many algorithms use different variations when the size of the data are odd or even, for example the exponentiation algorithm in Section 7.7 of the text.
Dynamic programming algorithms are based on recursion and optimization. In this class we looked at one problem with recursive algorithms - calculation efficiency.
The fibonacci sequence is a sequence of integers which appears frequently in the analysis of algorithms.
![]()
The sequence is defined recursively:
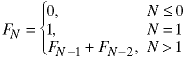
There are many ways to implement this algorithm. They differ widely in their computational efficiency, the amount of time required to calculate the N-th term in the sequence.
Note, the code for all of these examples is located in the
The fibonacci sequence can be calculated by means of a recursive function:
long int fib(int n) // Fibonacci sequence
{
if (n <= 0) return 0;
if (n == 1) return 1;
return fib(n-1) + fib(n-2);
} // end fib()
This function is short and elegant, but the computational times can be excessive. A program which implements this algorithm is contained in the CCC directory
/cs/cs2223/classes/class17/class17a.C
The attached script file shows that the execution time grows very rapidly. That is because the number of function calls required to calculate FN is FN, a rapidly-growing number.
An analytical solution for the fibonacci recurrence relation based on the method of undetermined coefficients is shown is shown in recurrence relations notes on the Notes page.
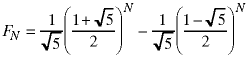
Because of the square roots, doubles are used instead of
long ints.
double fib(int n) // Fibonacci sequence
{
const double sqrt5 = sqrt(5.0); // constants
const double phi1 = (1 + sqrt5) / 2.0;
const double phi2 = (1 - sqrt5) / 2.0;
return (pow(phi1,n) - pow(phi2,n)) / sqrt5;
} // end fib()
A program which implements this algorithm is contained in the CCC directory
/cs/cs2223/classes/class17/class17b.C
The attached script file shows that the execution time is dramatically improved.
Whatever algorithm is used to calculate a fibonacci number, there is
no reason to do the calculation more than once. A typical dynamic programming
technique is to create an array of values and fill it only as far as is
needed. This function stores fibonacci numbers in an array and extends the
array only when a value is needed which is larger than any calculated in
the past. Note that this is an exact calculation using objects of the class
n_int introduced in Class 2.
n_int fib(int n) // Fibonacci sequence
{
static n_int fib[FIB_MAX + 1]; // be careful, this can become BIG
static int first_time = 1;
static int size = -1; // the last value calculated
if (first_time) // initialize the array
{
(fib[0]).make(0);
(fib[1]).make(1);
size = 1;
first_time = 0;
}
if (n > size) // calculate only what is needed, but remember it
{
for (int m = size+1; m <= n; m++) fib[m] = fib[m-1] + fib[m-2];
size = n;
}
return fib[n];
} // end fib()
A program which implements this algorithm is contained in the CCC directory
/cs/cs2223/classes/class17/class17c.C
The attached script file shows that the algorithm takes a while to calculate the values in the array, but once a number has been calculated, subsequent calls for the same value are quite fast. The price of this speed is the memory required to store the array.
In class, a great deal of interest was expressed about the method used for selecting which problem is graded. A copy of the program used to perform the selection has been placed in the CCC directory
/cs/cs2223/util/grade.C
This program uses the random number generator to produce a number between 1 and the number of the last problem in the set. It runs 15 times (to show there is no bias) before the actual value is chosen.
![]()