CS 2102 Homework Assignment #2
Assigned: Tuesday
October 31, 2006, 10:00
AM
Due: Tuesday November 07, 2006,
10:00 AM
Guidelines:
Now Available. Now that we have progressed to supporting input from the
keyboard, you must include the appropriate test cases with your homework
assignment. These test cases will be graded, so try to develop ones that are
meaningful for your problem.
Sample Data
For questions 3 and 4, you will need
to create some files on which to test your program. Please make sure that you
document properly the sample test cases that you come up with to test your
program. In an effort to help you with questions 3 and 4, I have come up with
the following sample data that you could use:
| Sample Input
File |
Sample Sequences File |
|
actgactgaacgtacgtacgggcatcagctgactacttatcgtacgtagct |
ctgaacgtac
cagctgatgcccgtacg
tacttatcg
agctgatcgtgctagtacca
tcagtcagt |
Description
- [20 pts.] Write a program that displays the prompt
"Enter a line of text and I will print it in reverse", then reads from the
keyboard a line of input (containing any number of characters including
white space) terminated by the ('\n') character (see p. 83 of the text).
Then create a String rev that represents the reverse of the line.
Finally, output rev back to the console, on a line by itself. Provide
within the documentation of your class the sample test cases that you used
to validate the correctness of your program.
- [15 pts.] Write a program that loads up a
String from a file called "input.txt". Note that in Eclipse, you will
need to create this file within the project where your homework is
being written. To do this, follow these instructions:
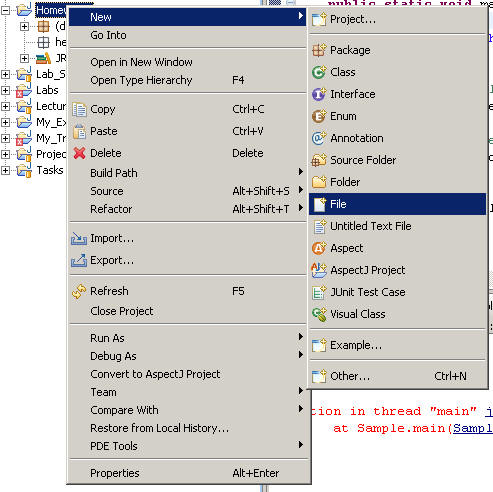 |
Right-click on the Project, select New -> File.
And when prompted, type the File Name "input.txt". Note that you will
create your file as a direct child of the Project on which you had
right-clicked. By placing the File here, you make it possible to
easily read the file by the statement:
Scanner sc = new Scanner (new File ("input.txt"));
Then you can read Strings and the like from this scanner object in
the same way as shown in class.
Check out the oct-31 package for an example of loading Strings
from a file. |
Now, assume that this input file is composed only of characters 'a', 'c',
't', and 'g' (Why? Check this out).
That is, there are no whitespace characters. Produce a report that
computes the percentage of these characters in the input file and output a
summary. Using the sample data provided above, the
following table should be output:
a:0.2549019607843137
c:0.2549019607843137
t:0.2549019607843137
g:0.23529411764705882
The most common letter is: a |
If two or more letters share the maximum
percentage, then you can choose to arbitrarily select one to be output in
the final statement.
Regarding formatting. You could choose to output the percentage as a raw
double (i.e., 0.2301019238487) or format as a true percentage (i.e.,
23.01019238487%) or reduced number of digits (i.e., 23%). The choice is
yours.
Provide within the documentation of your class the sample test cases that
you used to validate the correctness of your program.
- [25 pts.] Write a program that loads up a String from a file called
"input.txt". You should reuse the input file that you had used for
question 1. This file shall be composed only of characters 'a', 'c',
't', and 'g' (no whitespace characters will be present), thus it will be
composed of only a single String, which we'll refer to as target. A second file "sequences.txt"
shall also be created (in the same way as done for Problem2)
which contains a set of lines, each of which is a String composed
of characters 'a', 'c', 't', and 'g' (Why? Check this out).
Your task is to read String si from "sequences.txt",
one by one, and search for the first occurence (if any) of si
within target. If si is located as a
substring in target, then output "x..y + fragment" where:
- x represents the starting position of si within target, whose proper value
is 1
through target.length(). NOTE THAT THIS IS DIFFERENT FROM
THE INDEX CHARACTERS OF 0 THROUGH target.length()-1 AS WE HAVE SEEN IN
CLASS.
- y represents the ending position of si within target, whose proper
value is 1
through target.length()
- "+" is just a plus sign.
- fragment represents the first ten characters of the
sequence si followed by "...". If si
contains less than 10 characters in length, then you should output si
without the trailing "..." characters.
If the sequence si can't be found in target then output "UNMATCHED" on a line by
itself.
| Sample Output using
the above sample sequences: 6..15
+ ctgaacgtac
UNMATCHED
34..42 + tacttatcg
UNMATCHED
UNMATCHED |
Provide within the documentation of your class the sample test cases
that you used to validate the correctness of your program.
- [25 pts.] For this program, you will reuse the "input.txt' file
created for Problem1, and the "sequences.txt" file created for Problem2.
This time, your task is to read String si from "sequences.txt",
one by one, and search for the first occurrence (if any) of rev(si)
within target: You must assume that the target and si
Strings are composed only of 'a', 'c', 't', and 'g' characters.
- si
is the complement of si, created by swapping (a,t)
values and swapping (c,g) values. For example, if si
is "acggtcgattcg" then si
is "tgccagctaagc".
- rev(s) is defined as the reverse of a String. Thus
rev("acggtcgattcg") is "gcttagctggca".
So, rev(si)
for the String si="acggtcgattcg" is equal to the value
"cgaatcgaccgt". As with problem3, you are to produce a report. if rev(si)
is located as a
substring in target, then you should output "y..x - fragment" where:
of the form "y..x - fragment", where:
- x represents the starting position of rev(si) within target, whose proper value
is 1
through target.length(). NOTE THAT THIS IS DIFFERENT FROM
THE INDEX CHARACTERS OF 0 THROUGH target.length()-1 AS WE HAVE SEEN IN
CLASS.
- y represents the ending position of rev(si) within target, whose proper
value is 1
through target.length(). Note that y is greater than x
- "-" is just the minus sign.
- fragment represents the first ten characters of rev(si) followed by "...". If
rev(si) contains less than 10 characters in length, then you should output
rev(si) without the trailing "..." characters.
|
Sample Output using the above sample sequences:
UNMATCHED
31..15 - cgtacgggca...
UNMATCHED
UNMATCHED
9..1 - actgactga |
Provide within the documentation of your class the sample test cases
that you used to validate the correctness of your program.
- [15 pts.] Write a program that reads in a sequence of n
numbers from the keyboard. The user first is prompted "How many numbers
are in the sequence", to which they reply with an int value n
> 0. Then your program should read in n int values.
The task of your program is to (a) identify the longest sequence of
identical values in a row; and (b) print that value to the console. A
sample run of your program should look like the following:
How many numbers are in the sequence
6
Please enter 6 numbers separated by whitespace
3
4
4
4
5
5
The largest sequence of consecutive values is a sequence of 3
int with value 4. |
Provide within the documentation of your class the sample test cases
that you used to validate the correctness of your program.
If there exists multiple sequences that have
the same maximal longest sequence, then you can arbitrarily choose one
to output. For example, given the sequence "3 4 4 4 5 5 5" you could
choose to output either 4 or 5 as containing the largest sequence of
consecutive values.
Optional Non-Graded
- See if
you can combine Problem 3 and Problem 4 together
Deliverables
Your goal is to turnin the
Project files by Tuesday November 07th at 10:00 AM Further details will be
posted HERE showing the preferred means of uploading your solution to the TAs.
Please be aware that no late homeworks will be accepted. This means that we will
grade as zero any homework not submitted by the above turnin means.
Notes
- [11/06/06 8:30 PM] Clarification to problem 4. The fragment to be
reported is described as rev(si) but I don't show this in the sample output.
I have instructed the TAs to accept either form as part of the output. In
this homework, I have fixed the output as it should be.
- [11/05/06 12:40 AM] Clarification to problem 2 regarding formatting.
Sample data set provided for q3 and q4 to make it easier to debug your
solutions; also provided sample output with regards to this sample data.
- [11/05/06 12:14 AM] Clarification to problem 5 added.
- [11/01/06 5:14 PM] There was an error in the example for question 5. It
was told that there were '5' numbers in the sequence, when in fact there
were six. This has been updated (in red). Updated sample output for q3 and
q4.
- [10/31/06 1:12 AM] Homework2 completed. Homework2 guidelines to be
completed next...
- [10/28/06 11:54 PM] Homework2 to be posted here.
©2006 George T. Heineman