
Although the picture above implies that an entire compiler can be created by a compiler, in fact, compiler generators cannot yet generate entire compilers automatically.
Like compilers themselves, compiler generators are frequently separated into phases. For the front end of a compiler, the phases are often termed lexical analyzer generator, syntax analyzer generator (or parser generator) and semantic analyzer generator.
As the names imply, a lexical analyzer (or scanner) generator generates a lexical analyzer (or scanner), and a syntax analyzer (or parser) generator generates a syntax analyzer (or parser).
Generator phases for the back end of compilers are still very much a research topic although work has been done on code generator generators. Figure 1 shows how a compiler generator can be parametrized. The rectangular boxes show the standard compiler phases while the ovals show the corresponding generators. Figure 1 shows how a compiler generator can be parametrized. The rectangular boxes show the standard compiler phases while the ovals show the corresponding generators. The inputs to the ovals are termed metalanguages, which are languages that describe other languages. The front-end parts are shown grouped because often there is a single input file containing all the information needed to generate the front end of a compiler. In Figure 1, IR stands for Intermediate Representation.
Scanner generators are introduced in Section 1.3 and parser generators in Sec1.4. Attribute grammars and evaluator generators are introduced in Sec.1.5. For the back end, optimization and code generation will be discussed more from the point of view of automating or retargetting, and they are introduced in Section 1.6 and Section 1.7. This chapter is an overview of compiler tools. Algorithms and data structures are discussed within each chapter.
The first translator-like compilers were written in the late 1950's. Credit is given to FORTRAN as the first successfully compiled language. It took 18 person-years to develop the FORTRAN compiler because the language was being designed at the same time that it was being implemented, and since this was a first all around, the translation process was not well understood.
We can now design and implement compilers faster and better because (1) languages are better understood, (2) tools now exist for some of the phases of a compiler, and (3) data structures and algorithms are well-known for various compiler tasks.
By the late 1950's, computers and computer languages were proliferating. To create a compiler for N languages on M machines would require N * M programs if each were to be created separately. However, if the front-end of a compiler were to translate the source to a common intermediate language, and the back end of a compiler were to translate the source to a common intermediate language, and the back end of a compiler were to translate this intermediate language to the language of the machine, then (ideally) only N + M programs would be needed.
This was the philosophy behind UNCOL ( Sammet,1969 ), one of the first attempts at automating the process of compiler creation. UNCOL stood for Universal Computer-Oriented Language and was actually an intermediate language, not a compiler generator.
It proved difficult to design an intermediate language which was able to "capture" the variable aspects of different programming languages and different machines. This difficulty is still an issue in today's compiler tools. Front-end compiler generators began to appear in the early 1960's, and new generators continue to be created today.
Perhaps the best-known compiler tool is YACC, Yet Another Compiler-Compiler, written by Steve Johnson (1975). YACC was first created for the UNIX operating system and is associated with another tool called LEX ( Lesk and Schmidt, 1975 ) which generates a scanner, although it is not necessary to use a scanner generated by LEX to use YACC. Users can write their own scanners. LEX/YACC have been ported to other machines and operating systems.
Compiler tools whose metalanguages include attribute grammars began to appear in the late 1970's and 1980's. GAG ( Kastens et al., 1982) are based upon attribute grammar descriptions.
The PQCC ( Wulf et al., 1975 ) project and others have undertaken the difficult task of generating the back end of a compiler.
Like all successful software, the best compiler tools hide implementation details from the user. Since almost all tools really generate only part of the compiler, it is also very important that the tool be able to be integrated into the parts of the compiler not generated by the tool.
The largest group of compiler generators create the front-end phases of a compiler, with the back-end phases still being written by hand. Research continues into the back-end generation issues.
Four characteristics will be identified and discussed here:
Some metalanguages can be used to describe themselves. The term unstratified refers to the self-description property of a metalanguage. A good metalanguage is unstratified.
A metalanguage should be "integrated", that is, have similar notations for functions throughout the different parts of the tool. For example, "=" might be used as the assignment operator for the regular expressions part, the context-free part, and the semantic function part. LEX and YACC use "%%" as separators between the different sections for all parts of the metalanguage.
Like programming languages themselves, the metalanguage should not contain constructs that are easily error-prone such as comments that extend over line boundaries.
A good metalanguage is difficult to define and probably a matter of taste. This section has mentioned properties that all metalanguages should have.
Documentation describes the tool and, as for any large or complex software package, consists of two parts: (1) the user manual, and (2) the system documentation that the describes the technical aspects of the tool. The boundary between these two can be hazy, with technical details needed to know how to use it, and using it necessary to understand the technical aspects.
Documentation for even the most widely used tools is often incomplete and/or unclear although the situation is improving.
The manual should be well-written and clear. A cookbook example should be included which takes the user through an application of the system. Many compiler tool manuals include a cookbook example for a so-called calculator - often a language consisting of assignment statements with right-hand sides which are arithmetic expressions.
The cookbook example should be complete. Many cookbook examples leave "something" out, and the user is left wondering if the authors beta-tested the manual along with the software, or if they hastily wrote the manual the day before the tool was released.
The documentation should be correct. Even the most innocent typographical errors can confuse a new user.
Most compiler tools include facilities for making changes to the generated scanner or parser (See Functionality ). To do this, the user needs technical details about the tool. In addition, if the tool is to be maintained by a system manager, he or she will need the technical description.
Like metalanguages, good documentation is also difficult to define. With a wide range of users who have an even wider range of backgrounds, the documentation may always be seen as too elementary or too complex by the users at the ends of the spectrum.
Many generated compiler parts consist of two "pieces". The first piece is the table, graph or program stub generated by the tool from the metalanguage input. The second piece is a driver program that reads input and consults the table (or graph or program) for the next action.
Some tools are parametrized. They can produce separate scanners and separate parsers. Other tools produce only one result - the scanner/parser/ semantic analyzer.
Most tools either generate a semantic analyzer or allow the user to write semantic routines that are executed during parsing. When the parser recognizes a construct such as, say, an assignment statement, this routine is executed. Some tools allow the user to input the semantics in the form of an attribute grammar.
First, the tool should be robust; a mistake by the user shouldn't leave the user hanging with an execution error.
Second, a tool should be efficient, both in time and in space. An example of an efficient tool would be one which produced the tables implemented as a two-dimensional array. As we shall see, parse tables are sparse, and for real programming languages they are large. Data structures appropriate to sparse matrices are required.
Also, a good tool is integrated with the remainder of the compiler. And a good tool has two modes of use - one for the novice that includes lots of help and prompts and one for the sophisticated user.
We will distinguish between these by calling the generated tables/program the tool output, and the result when the driver executes on this tool output, the resulting compiler output.
Some tools, notably LEX and YACC produce no resulting compiler output as a default when the source program is correct. This makes sense when the resulting compiler is finally integrated, debugged and ready to use - after all, most programmers don't really want to see the output from intermediate phases of the compiler.
However, more feedback is needed in the debugging stages, and most tools will allow the user to add routines for temporary output. The compiler project for this course will include intermediate outputs as we build the compiler piece by piece.


One necessary output is good error messages. The compiler designer should receive useful feedback when using the tool incorrectly.
Much research is currently being devoted to producing good error messages with compilers created by compiler tools. Realize that compile-time errors must be entered into erroneous positions in the generated table or program stub.
One technique which has met with modest success is the use of "error productions" in the input grammar for the language. That is, a regular expression or BNF grammar production is input which, in the generated compiler, "recognizes" an incorrect construct. The accompanying semantic action produces the error message.
A scanner, or lexical analyzer, finds the elementary pieces of the program called tokens.
The metalanguage to a scanner generator consists of regular expressions. These regular expressions describe tokens that the generated scanner will then be able to find when a source program is input.
Example 1 shows the regular expressions for the tokens for the components of typical assignment statements.
Example 2 shows an input and output for the generated scanner.
Module 3 discusses the details of generating such a scanner.
Example 4 shows the results when the generated parser is used. (The nonterminal Expression has been abbreviated Expr. ) The tokens have been parsed, producing a parse tree.
As with the generated scanner, the output is produced only during the debugging of the generated compiler pieces.
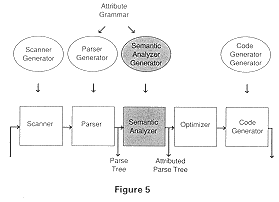
The input to a semantic analyzer generator is often an attribute grammar. Attribute grammars are a common specification language for semantic analysis. Because an attribute grammar is a context-free grammar with the addition of equations called semantic functions, the input in Figure 5 is shown going to both the parser generator an the semantic analyzer generator. The context-free grammar is input to the parser generator, and the semantic functions are input to the semantic analyzer generator.
The semantic analysis phase of a compiler performs many diverse tasks, rather than a single task as in scanning and parsing. Many, many variables called attributes are needed to describe these tasks. In Example 5 we show only two attributes, Use and Def, which describe information about the use and definition of the variables used in the program.
This information can be used to finish parsing, perhaps by warning the user that a variable is used before it is defined.
This information can also be used by the optimization phase of the compiler, perhaps by eliminating a variable that was defined but never used. Example 5 shows an attribute grammar for the assignment statement grammar.
Example 6 shows the results produced by the generated semantic analyzer generator.
Here, we show an abstract syntax tree (or abstract structure tree. It removes some of the intermediate categories and captures the elementary structure. . Each leaf and non-leaf represents a token; leaves are operands and non-leaves are operators. The assignment statement:
X := X + 1
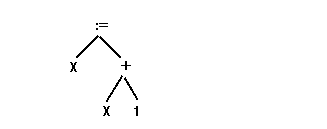
Also, the code generation phase may make optimizations, both before and after executable code is selected. Optimizations on the generated code are called peephole optimizations.
The optimization phase changes the intermediate representation so that the code ultimately generated executes faster or takes up less space or uses special machine parts in improved ways.
Optimization can calculate attribute values (as in the calculation of use def in Section 1.5. ), or it can make structural changes to the tree, or it may even change the intermediate representation to a graph and make changes to the graph.
Modules 6, 7 and 8 discuss these various options. We will defer examples until those sections.
There are other steps which are taken towards automating the code generation process that are something less than a full-fledged code generator generator.
A first step toward automating the code generation process, and good programming style as well, is to separate the code generation algorithm from the machine code itself. This allows tables of (IR,code) ordered pairs to be created and used and perhaps cha nged to be ported to another machine.
The code generation algorithm then consists of a driver inputting the intermediate code and consulting the table, just as in Figure 2. The difference is that the table is created by hand, rather than generated from a descript ion of the machine.
Example 7 shows such a code generator that might be termed retargetable. Input to the code generator is a set of ordered pairs. The first element of the ordered pair is a description of a subtree of the intermedia te representation to be matched; the second element is the code to be output on such a match.
The remainder of this course presents algorithms and data structures for performing and/or generating these compiler phases. Where possible, mainly for the front end, we focus on automating the compiling process. Where automation is more difficult, mainly in the back-end, we focus on techniques for efficient processing,
Compilers are an interesting, integrated computer science topic, encompassing concepts from data structures, algorithms, finite automata, computability, computer architecture and software engineering, to name a few. In addition, topics in compiler design continue to evolve: new architectures (see Chapter 12 ) require new techniques; the automation process continues to be researched and developed; error processing techniques continue to improve.
Building the right tools and using good design produce good compilers.