| 5.0 Introduction |
5.1 Metalanguage for Bottom-Up Parser Generation
The metalanguage for a bottom-up parser is not as restrictive as that for a top-down parser. Left-recursion is not a problem because the tree is built from the leaves up.
Strictly speaking, right-recursion, where the left-hand nonterminal is repeated at the end of the right-hand side, is not a problem. However, as we will see, the bottom-up parsing method described here pushes terminals and nonterminals on a stack until an appropriate right-hand side is found, and right-recursion can be somewhat inefficient in that many symbols must be pushed before a right-hand side is found.
Example 1 BNF for bottom-up parsing
Program --> Statements
Statements --> Statement Statements | Statement
Statement --> AsstStmt
AsstStmt --> Identifier : = Expression
Expression --> Expression + Term | Expression-
Term | Term
Term --> Term * Factor | Term / Factor |
Factor
Factor --> ( Expression ) | Identifier |
Literal
The BNF shown in Example 1 states that a program consists of a sequence of statements, each of which is an assignment statement with a right-hand side consisting of an arithmetic expression. This BNF is input to the parser generator to produce tables which are then accessed by the driver as the input is read.
Example 2 Input to parser generator
Program --> Statements
Statements --> Statement Statements | Statement
Statement --> AsstStmt ;
AsstStmt --> Identifier : = Expression-Term | Term
Expression --> Expression + Term | Expression-
Term | Term
Term --> Term * Factor | Term / Factor |
Factor
Factor --> (Expression) | Identifier |
Literal
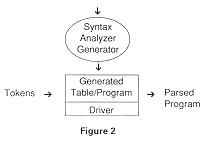
Using a context-free grammar, one can describe the structure of a program, that is, the function of the generated parser. The parser generator converts the BNF into tables. The form of the tables depends upon whether the generated parser is a top-down parser or a bottom-up parser. Top-down parsers are easy to generate; bottom up parsers are more difficult to generate.
At compile-time, the driver reads input tokens, consults the table and creates a parse from the bottom-up.
We will describe the driver first, as usual, The method described here is a shift-reduce parsing method; that is, we parse by shifting input onto the stack until we have enough to recognize an appropriate right-hand side of production. The sequence on the stack which is ready to be reduced is called the handle.
The handle is a right-hand side of a production, taking into account the rules of the grammar. For example, an expression would not use a + b as the handle if the string were a + b * c. We will see that our method finds the correct handle.
![]()