


Prof. Carolina Ruiz and Ahmedul Kabir
Due Date:
Canvas submission by Monday, Sept. 11th, 2017 at 11:00 pm.
Project Goal:
The goal of this homework is to help you understand exactly how different search strategies work. You will implement each of eight graph search algorithms. Among the searches are basic searches, heuristically informed searches, and optimal searches.
In particular, the search strategies included in this project are:
- Depth 1st search
- Breadth 1st search
- Depth-limited search (use depth-limit = 2)
- Iterative deepening search (show all iterations, not just
the iteration that succeeds)
- Uniform cost search (= Branch-and-bound)
- Greedy search (= Best 1st search)
- A*
- Hill-climbing (use the version of hill-climbing without backtracking)
- Beam search (use w = 2)
Project Assignment:
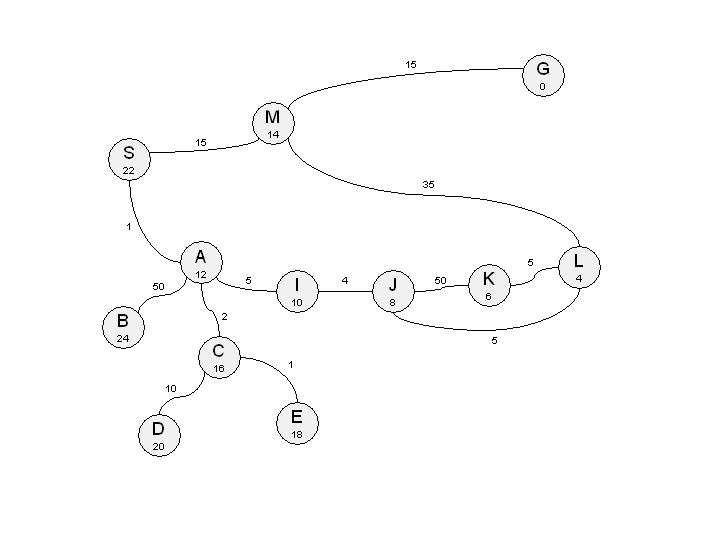
For illustration purposes, suppose that you need to find a path between
S and G in the following graph.
See the description of this graph input format
below.
S M 15
S A 1
M G 15
A I 5
A C 2
A B 50
C E 1
C D 10
I J 4
J K 50
J L 5
K L 5
L M 35
#####
S 22
M 14
I 10
J 8
K 6
L 4
E 18
C 16
D 20
A 12
B 24
A picture of this graph is included below. Note that the (under)estimated
distance of each node to the goal is included inside the node. (Special
thanks to Peter Mardziel for creating this picture).
Write a computer program that implements the general search algorithm described in class and in the textbook.
- You may use a programming language of your choice.
- Your program must adhere to the Input and Output Specifications.
- Your program must follow the requirements described in the
your code section below.
- Your program must demonstrate each and every one of
the search methods listed above.
- All searches must terminate.
- No search results should contain any loops.
Input Specifications:
Your program must read the graph to be searched from a file. The format of the file is as follows:
The graph file has two sections. The first section describes the topology of the graph and the weights (costs, distances) of the paths between nodes. The second section provides heuristic estimates for the distances from each node to the goal node.
In the first section, each line contains all the information about one connection between two adjacent nodes. Each of these lines has 3 fields, and each field is separated by whitespace.
- The first field is the name of a node. All nodes are named by a single capital letter. Therefore, the length of the first field is always one byte (one character).
- The second field is also the name of a node, and is also one character long. In the graph, this node is adjacent to the node named in the first field.
- The third field is the actual length of the connection between the node named in the first field and the node named in the second field. It is a float value.
In total, the first section will contain as many lines as there are connections in the graph. You may assume that every graph contains a node named 'S' and a node named 'G'. You may also assume that the graph is finite (of course). These are the starting and goal nodes, respectively. After the first section there will be a line separating the two sections. This line will contain only 5 pound signs. i.e. "#####"
The second section contains heuristic information about each node in the graph (except for the goal node). Only the heuristically informed methods should use this information. Each line has 2 fields.
- The first field is the name of a node. Again, it is one character.
- The second field is the estimated distance from the node named in the first field to the goal.
As an example consider the graph in the file: graph.txt
S A 3.0
S D 4.0
A B 4.0
B C 4.0
A D 5.0
B E 5.0
D E 2.0
F E 4.0
G F 3.0
#####
S 11.0
A 10.4
D 8.9
B 6.7
E 6.9
C 4.0
F 3.0
Please note that after F 3.0 there is a newline character.
Also, note that the (under)estimate of the distance between the goal state
G and itself is always 0 and hence not included in the file.
Output Specifications:
Your program should output the trace of EACH search method, in the
order listed above.
In particular, you should print:
- (1) the name of the search method;
- (2) the name of each node in the order it was EXPANDED, (not just explored); and
- (3) the state of the "queue" when the node was expanded.
In uninformed search methods, the children of a node should be
considered ordered in alphabetical order, that is if a node has
children D, B, and F, then B will considered the 1st (or leftmost)
child, D the 2nd (or middle) child, and F the last (or rightmost) child
of the node. In informed search methods where cost/value of a path is
considered (e.g., uniform (= branch-and-bound),
greedy search, A*, hill climbing, and beam search), and you need to decide
the order of the paths in the queue according to their values (either f, g, or h
values), follow the sorting procedure below:
- If two paths have different values then
- put the one with the lowest value first (= front) in the queue
(e.g. 15<L,M,S> will go before 24<A,S>)
- else (* the two paths have the same value *)
- If the two paths end at different nodes then
- put first (= front) in the queue the one that ends at the node that
is first in alphabetical order
(e.g. 15<L,J,I,S> would go before 15<M,S>)
- else (* the two paths end at the same node *)
- If the two paths are of different length then
- put first (= front) in the queue the shortest one
(e.g. 15<M,S> will go before 15<M,L,S>)
- else (* the two paths end at the same node and are of the same length *)
- sort the two paths in lexicographic order
(e.g. 15<M,B,S> will go before 15<M,L,S>)
For example, the output of your program when the input is the
graph described in graph.txt
should be:
- Depth 1st search
Expanded Queue
S [<S>]
A [<A,S> <D,S>]
B [<B,A,S> <D,A,S> <D,S>]
C [<C,B,A,S> <E,B,A,S> <D,A,S> <D,S>]
E [<E,B,A,S> <D,A,S> <D,S>]
D [<D,E,B,A,S> <F,E,B,A,S> <D,A,S> <D,S>]
F [<F,E,B,A,S> <D,A,S> <D,S>]
G [<G,F,E,B,A,S> <D,A,S> <D,S>]
goal reached!
- Breadth 1st search
Expanded Queue
S [<S>]
A [<A,S> <D,S>]
D [<D,S> <B,A,S> <D,A,S>]
B [<B,A,S> <D,A,S> <A,D,S> <E,D,S>]
D [<D,A,S> <A,D,S> <E,D,S> <C,B,A,S> <E,B,A,S>]
A [<A,D,S> <E,D,S> <C,B,A,S> <E,B,A,S> <E,D,A,S>]
E [<E,D,S> <C,B,A,S> <E,B,A,S> <E,D,A,S> <B,A,D,S>]
C [<C,B,A,S> <E,B,A,S> <E,D,A,S> <B,A,D,S> <B,E,D,S> <F,E,D,S>]
E [<E,B,A,S> <E,D,A,S> <B,A,D,S> <B,E,D,S> <F,E,D,S>]
E [<E,D,A,S> <B,A,D,S> <B,E,D,S> <F,E,D,S> <D,E,B,A,S> <F,E,B,A,S>]
B [<B,A,D,S> <B,E,D,S> <F,E,D,S> <D,E,B,A,S> <F,E,B,A,S> <B,E,D,A,S> <F,E,D,A,S>]
B [<B,E,D,S> <F,E,D,S> <D,E,B,A,S> <F,E,B,A,S> <B,E,D,A,S> <F,E,D,A,S> <C,B,A,D,S> <E,B,A,D,S>]
F [<F,E,D,S> <D,E,B,A,S> <F,E,B,A,S> <B,E,D,A,S> <F,E,D,A,S> <C,B,A,D,S> <E,B,A,D,S> <A,B,E,D,S> <C,B,E,D,S>]
D [<D,E,B,A,S> <F,E,B,A,S> <B,E,D,A,S> <F,E,D,A,S> <C,B,A,D,S> <E,B,A,D,S> <A,B,E,D,S> <C,B,E,D,S> <G,F,E,D,S>]
F [<F,E,B,A,S> <B,E,D,A,S> <F,E,D,A,S> <C,B,A,D,S> <E,B,A,D,S> <A,B,E,D,S> <C,B,E,D,S> <G,F,E,D,S>]
B [<B,E,D,A,S> <F,E,D,A,S> <C,B,A,D,S> <E,B,A,D,S> <A,B,E,D,S> <C,B,E,D,S> <G,F,E,D,S> <G,F,E,B,A,S>]
F [<F,E,D,A,S> <C,B,A,D,S> <E,B,A,D,S> <A,B,E,D,S> <C,B,E,D,S> <G,F,E,D,S> <G,F,E,B,A,S> <C,B,E,D,A,S>]
C [<C,B,A,D,S> <E,B,A,D,S> <A,B,E,D,S> <C,B,E,D,S> <G,F,E,D,S> <G,F,E,B,A,S> <C,B,E,D,A,S> <G,F,E,D,A,S>]
E [<E,B,A,D,S> <A,B,E,D,S> <C,B,E,D,S> <G,F,E,D,S> <G,F,E,B,A,S> <C,B,E,D,A,S> <G,F,E,D,A,S>]
A [<A,B,E,D,S> <C,B,E,D,S> <G,F,E,D,S> <G,F,E,B,A,S> <C,B,E,D,A,S> <G,F,E,D,A,S> <F,E,B,A,D,S>]
C [<C,B,E,D,S> <G,F,E,D,S> <G,F,E,B,A,S> <C,B,E,D,A,S> <G,F,E,D,A,S> <F,E,B,A,D,S>]
G [<G,F,E,D,S> <G,F,E,B,A,S> <C,B,E,D,A,S> <G,F,E,D,A,S> <F,E,B,A,D,S>]
goal reached!
- Depth-limited search (depth-limit = 2)
Expanded Queue
S [<S>]
A [<A,S> <D,S>]
B [<B,A,S> <D,A,S> <D,S>]
D [<D,A,S> <D,S>]
D [<D,S>]
A [<A,D,S> <E,D,S>]
E [<E,D,S>]
- Iterative deepening search
Expanded Queue
L=0 S [<S>]
L=1 S [<S>]
A [<A,S> <D,S>]
D [<D,S>]
L=2 S [<S>]
A [<A,S> <D,S>]
B [<B,A,S> <D,A,S> <D,S>]
D [<D,A,S> <D,S>]
D [<D,S>]
A [<A,D,S> <E,D,S>]
E [<E,D,S>]
L=3 S [<S>]
A [<A,S> <D,S>]
B [<B,A,S> <D,A,S> <D,S>]
C [<C,B,A,S> <E,B,A,S> <D,A,S> <D,S>]
E [<E,B,A,S> <D,A,S> <D,S>]
D [<D,A,S> <D,S>]
E [<E,D,A,S> <D,S>]
D [<D,S>]
A [<A,D,S> <E,D,S>]
B [<B,A,D,S> <E,D,S>]
E [<E,D,S>]
B [<B,E,D,S> <F,E,D,S>]
F [<F,E,D,S>]
[]
L=4 S [<S>]
A [<A,S> <D,S>]
B [<B,A,S> <D,A,S> <D,S>]
C [<C,B,A,S> <E,B,A,S> <D,A,S> <D,S>]
E [<E,B,A,S> <D,A,S> <D,S>]
D [<D,E,B,A,S> <F,E,B,A,S> <D,A,S> <D,S>]
F [<F,E,B,A,S> <D,A,S> <D,S>]
D [<D,A,S> <D,S>]
E [<E,D,A,S> <D,S>]
B [<B,E,D,A,S> <F,E,D,A,S> <D,S>]
F [<F,E,D,A,S> <D,S>]
D [<D,S>]
A [<A,D,S> <E,D,S>]
B [<B,A,D,S> <E,D,S>]
C [<C,B,A,D,S> <E,B,A,D,S> <E,D,S>]
E [<E,B,A,D,S> <E,D,S>]
E [<E,D,S>]
B [<B,E,D,S> <F,E,D,S>]
A [<A,B,E,D,S> <C,B,E,D,S> <F,E,D,S>]
C [<C,B,E,D,S> <F,E,D,S>]
F [<F,E,D,S>]
G [<G,F,E,D,S>]
goal reached!
- Uniform Search (Branch-and-bound)
Expanded Queue
S [0<S>]
A [3<A,S> 4<D,S>]
D [4<D,S> 7<B,A,S> 8<D,A,S>]
E [6<E,D,S> 7<B,A,S> 8<D,A,S> 9<A,D,S>]
B [7<B,A,S> 8<D,A,S> 9<A,D,S> 10<F,E,D,S> 11<B,E,D,S>]
D [8<D,A,S> 9<A,D,S> 10<F,E,D,S> 11<B,E,D,S> 11<C,B,A,S> 12<E,B,A,S>]
A [9<A,D,S> 10<E,D,A,S> 10<F,E,D,S> 11<B,E,D,S> 11<C,B,A,S> 12<E,B,A,S>]
E [10<E,D,A,S> 10<F,E,D,S> 11<B,E,D,S> 11<C,B,A,S> 12<E,B,A,S> 13<B,A,D,S>]
F [10<F,E,D,S> 11<B,E,D,S> 11<C,B,A,S> 12<E,B,A,S> 13<B,A,D,S> 14<F,E,D,A,S> 15<B,E,D,A,S>]
B [11<B,E,D,S> 11<C,B,A,S> 12<E,B,A,S> 13<B,A,D,S> 13<G,F,E,D,S> 14<F,E,D,A,S> 15<B,E,D,A,S>]
C [11<C,B,A,S> 12<E,B,A,S> 13<B,A,D,S> 13<G,F,E,D,S> 14<F,E,D,A,S> 15<A,B,E,D,S> 15<B,E,D,A,S>15 <C,B,E,D,S>]
E [12<E,B,A,S> 13<B,A,D,S> 13<G,F,E,D,S> 14<F,E,D,A,S> 15<A,B,E,D,S> 15<B,E,D,A,S> 15<C,B,E,D,S>]
B [13<B,A,D,S> 13<G,F,E,D,S> 14<D,E,B,A,S> 14<F,E,D,A,S> 15<A,B,E,D,S> 15<B,E,D,A,S> 15<C,B,E,D,S> 16<F,E,B,A,S>]
G [13<G,F,E,D,S> 14<D,E,B,A,S> 14<F,E,D,A,S> 15<A,B,E,D,S> 15<B,E,D,A,S> 15<C,B,E,D,S> 16<F,E,B,A,S> 17<C,B,A,D,S> 18<E,B,A,D,S>]
goal reached!
- Greedy search
Expanded Queue
S [11.0<S>]
D [8.9<D,S> 10.4<A,S>]
E [6.9<E,D,S> 10.4<A,S> 10.4<A,D,S>]
F [3.0<F,E,D,S> 6.7<B,E,D,S> 10.4<A,S> 10.4<A,D,S>]
G [0<G,F,E,D,S> 6.7<B,E,D,S> 10.4<A,S> 10.4<A,D,S>]
goal reached!
- A*
Expanded Queue
S [11.0<S>]
D [12.9<D,S> 13.4<A,S>]
E [12.9<E,D,S> 13.4<A,S>]
F [13<F,E,D,S> 13.4<A,S> 17.7<B,E,D,S>]
G [13<G,F,E,D,S> 13.4<A,S> 17.7<B,E,D,S>]
goal reached!
- Beam search (w = 2)
Expanded Queue
S [11.0<S>]
A [10.4<A,S> 8.9<D,S>]
D [8.9<D,S> 6.7<B,A,S> 8.9<D,A,S>]
B [6.7<B,A,S> 6.9<E,D,S>]
E [6.9<E,D,S> 4<C,B,A,S> 6.9<E,B,A,S>]
C [4<C,B,A,S> 3<F,E,D,S>]
F [3<F,E,D,S>]
G [0<G,F,E,D,S>]
goal reached!
The search ends when the goal node is expanded. Therefore if the goal
is reached, it will be the last node listed. Since some of these
searches are not complete (even for finite graphs!) it will be possible
that the goal is not found. In this case, the trace will end with
the last node expanded before the search terminated,
followed by a "failure to find path between S and G" message.
For another example of the expected output see
Solutions to old HW1.
(The search trees are depicted there
just for illustration purposes, but are not part of the output.
Note also that those solutions use a different convention for depth-limited
search and iterative deepening - the level
numbers there are "inflated" by 1, as discussed in class.
Ignore the Hill-climbing output as it uses backtracking
while in this project you are using Hill-Climbing without backtracking.)
Your Code:
Your program (or an accompanying script, as described in your program documentation) must accept the name of the file to read the graph from.
For example, your program could be run by typing "java Search graph.txt" or "search graph.txt" or "runsearch graph.txt"
Your solution must use a general search procedure and a general data structure (that we'll refer to in class and in this project statement as "the queue") so that each of the search strategies calls the general search procedure with a parameter specifying which search method to use. That is, you must have a procedure that implements the following pseudo-code (adapted from
Russell's and Norvig's textbook):
function General_Search (problem, search-method) returns either a solution or failure
queue = Make-Queue(Make-Node(problem.initial-state))
loop do
if queue is empty then return failure
node =Remove-Front(queue)
if State[node] is a solution of problem then return State[node]
opened-nodes= Expand(node)
queue= opened-nodes added to queue according to search-method
end
Your procedure implementing this pseudo-code must be named General_Search as shown
above.
More details about this general procedure will be given in class.
For an example of how to implement each of the search strategies as a call to this general
procedure, see
Russell's and Norvig's online code.
Although you are welcome to look at their code to guide the design of your program,
you MUST submit your own original code.
Note that in order to avoid loops, you need to store not just the name of node
being explored in your "queue", but also the path used to arrive to that node from the source node, as it is done in the sample traces shown above.
Project Submission:
Submit on Canvas
the following files by the submission deadline:
- The source code for your program
- Any ancillary files that your program requires
- A readme.txt file containing
the names of the three students in the group AND
instructions for compiling and/or running your program
- The output produced by your program on the
sample file graph.txt.
- The output produced by your program on the
sample file second_graph.txt.
Project Grading:
- Your program will be tested using test files other than graph.txt and
second.txt.
- 20 points will be for creating the general search procedure as described
above and making each of the search methods be a call to
this general procedure.
- Each search method that works successfully and that has been correctly implemented
will be worth 10 points. These 10 points are distributed in the following way:
- 3 points for correctly calling the general search procedure
General_Search.
- 3 points for handling the queue correctly according to the particular
search method
- 4 for running correctly over the 3 test files
- Total: 100 points.
Optional Bonus Problem:
- (10 points) Construct an example of a graph for which all the search methods above produce
different traces. That is, no two search methods produce the same ordered list of
expanded nodes.
Provide your answer in the input format specified above.
Show the output produce by your program on this input.
Submit in a file named "BonusProblem.txt" together with your
Canvas project submission by the project deadline.