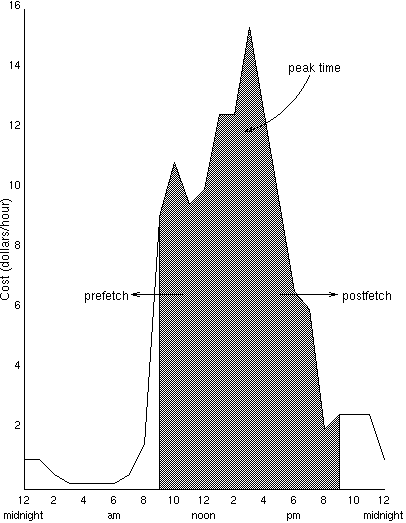
Figure 1: VUW Web Traffic for a Typical Day (Dollars/Hour)
Craig E. Wills [HREF1] Worcester Polytechnic Institute, 100 Institute Road, Worcester, Massachusetts 01609, U.S.A. cew@cs.wpi.edu
Paul Thomas [HREF2], Victoria University of Wellington, P.O. Box 600, Wellington, New Zealand. paul.thomas@vuw.ac.nz
Caching proxies in the World Wide Web have traditionally been used to reduce overall latency and bandwidth by keeping copies of popular documents closer to the client than the server. This paper describes work to make such caches more sensitive to differential Internet costs, in particular the distinction between relatively cheap ``off-peak'' and expensive ``on-peak'' network traffic. The idea is to develop algorithms that actively shape traffic patterns. Three methods were implemented and tested: prefetching, fetching a document ahead of an anticipated on-peak request; postfetching, fetching a document during off-peak time after an on-peak request; and not fetching, returning a potentially stale, cached copy from cache when retrieving a new copy may prove expensive.
The results show that postfetching is the most deterministic approach for reducing costs at the expense of some user inconvenience. Prefetching is not a desirable approach in the general case, but could be effectively used on a limited basis for objects with known change characteristics. The not fetching approach shows a small cost reduction with a comparable increase in stale cache objects served.
The explosive growth of the World Wide Web (WWW) in recent years has seen demand grow many times faster than available network bandwidth and as a result the use of Web caches, pieces of software dedicated to keeping Web objects closer to users requesting them, has grown rapidly. These caches have reduced the cost of Web usage by reducing the need to retrieve objects from origin servers.
This paper details a project to further reduce the cost of Web usage for a medium-sized community, the community of staff and graduate students at Victoria University of Wellington (VUW) using a single Web cache. Internet costs for Victoria University, in common with many other sites in New Zealand, are based on two factors: the number of bytes transferred across the network (in or out), and the time at which those bytes are transferred. It is this differential between expensive ``peak'' bytes and cheap ``off-peak'' bytes that this project seeks to exploit.
Motivated by this cost differential, we developed a simulator for the popular Squid Web cache [7] to test three approaches for reducing overall Web retrieval costs:
The remainder of this paper describes related work followed by descriptions of the network cost model and Web traffic characteristics at VUW. The paper goes on to describe the policies we tested and the results obtained using a simulator driven by actual proxy logs from VUW. The paper concludes with a summary of our work.
Prefetching in caches for database or memory systems is a well-studied problem [9], but one that differs substantially from the problem of prefetching in a cache for Web objects. Memory systems, and to a lesser extent traditional databases, feature a uniform cost to retrieve any object, and typically work with uniform-sized objects. These properties do not hold for Web caching and prefetching.
Research to date in Web prefetching has generally been concerned with reducing latency, not traffic. [2] proposes a simple scheme where proxies parse HTML documents that they fetch, extract any references to other documents (embedded images, linked objects), and retrieve these referenced objects while they would otherwise be idle. This approach does reduce latency, but transfers around three times as many bytes.
More sophisticated prefetching techniques are discussed in [1, 8, 3]. With these techniques, servers compute the most likely next access for a client, based on accesses to date, and clients explicitly request either the names of candidate objects or the objects themselves. This approach requires the cooperation of both clients and servers (and possibly proxies in between, depending on the implementation), unlike our work; however, the interaction between user, client, and server makes possible more sophisticated reasoning about a user's behaviour. [8] suggests that a proxy could initiate the prefetching, but there is little discussion of this possibility. Again, there is more concern with reducing perceived latency than with conserving bandwidth, although the bandwidth requirements for these schemes are typically much less than those of [2].
[6] takes a similar approach, but explicitly considers after-hours prefetching as a means to reduce overall cost and introduces prefetching as a function of a proxy, not a client (although server-side cooperation is still required). This is the closest model to our work; however, it does not take into account cache expiration time or replacement, which may pose a significant problem if documents are prefetched far ahead of their next reference. The work also has clients prefetching a number of objects appropriate to their access patterns, so that an infrequent visitor gets less objects. This explicit adjustment is not made in our work.
Victoria University, in common with many other New Zealand sites, is charged for Internet usage on the number of bytes of traffic transferred, both inbound and outbound. Each byte is charged at one of two rates: a more expensive ``on-peak'' rate for traffic generated or accepted between 9am and 8pm, Monday through Sunday, and a much cheaper ``off-peak'' rate for traffic generated or accepted between 8pm and 9am. The on-peak to off-peak cost ratio is 3.6:1.
Although this charging scheme is not commonplace worldwide, the model can be adapted to other situations. For example, in the case of a business with a low-bandwidth connection to the Internet, high-usage periods could be regarded as more expensive and it is desirable to shift as much traffic as possible to the lower-usage periods. Mobile computing [4] can also be modeled; peak times may represent times where the mobile computer is further from its base, or where the (typically low) bandwidth available is consumed by interactive applications. Cheaper, off-peak times are when more bandwidth is available.
Figure 1 gives an overview of the cost of traffic over the course of a typical day as seen by a proxy cache at VUW. The shaded area represents cost during peak time; as may be expected, the cost rises sharply with the start of peak time at 9am, and drops just as sharply with the end of peak time at 8pm. To reduce the cost of Web usage, it is necessary to reduce the area under this curve; rather than reduce the number of requests we attempt to shift traffic from the more expensive shaded area.
Figure 1: VUW Web Traffic for a Typical Day (Dollars/Hour)
Tables 1 and 2 give a more detailed breakdown of cache activity. ``HITs'' are those objects returned from the cache with no additional checking; ``MISSes'' are requests for objects not in the cache; and the pair of ``FRESH'' and ``STALE'' are requests for objects which were cached, but considered to be too old to return immediately. These data suggest that the three potential policies are worth investigation: prefetching can reduce the 15% of peak byte traffic in categories FRESH during peak time (FRESH-P) and STALE during that period (STALE-P), by ensuring that cached copies have been recently refreshed and are considered fresh; postfetching can reduce MISS-P, which accounts for 65% of peak traffic; and not fetching can reduce FRESH-P and STALE-P, again 15% of peak traffic, by converting these to HITs.
We evaluate the various caching policies by using these costs to compute an overall cost, which accounts for the amount of network traffic due to each of these costs and whether this traffic occurs during off- or on-peak times. For purposes of cost calculation we use a ratio of 3.6:1 (actually 0.72:0.20) for on-peak to off-peak costs measured in average dollars per day. This was the cost ratio at the time of our study. Because the not fetching policies may cause stale objects to be served from cache we also report the additional stale objects returned by these policies. To better analyze the sensitivity of our results to different cost ratios we present the total number of network bytes for off- and on-peak times.
The following discusses our results for four types of policies: baseline policies, which do not account for differential network costs; prefetching policies, which attempt to validate cached objects during off-peak that are expected to be used during on-peak; postfetching policies, which delay the retrieval of larger objects requested during on-peak to off-peak; and not fetching policies, which knowingly supply stale cached objects during on-peak times to avoid network costs. These policies were tested with VUW Squid proxy logs collected from 28 February to 12 March 1998.
As a baseline for our study, we first examined three caching policies:
Table 3 shows the results for these policies. The table shows a total cost of $194 per average day to use the default policy with cache misses accounting for most of these costs. The table also shows the cost savings due to cached objects that need to be validated, but not retrieved again (ims304) and cache hits. These cost savings are not reflected in the overall cost, but represent the savings compared to having no cache. Note that ims304 responses both incur a cost the for headers returned and a savings for the contents not needing to be retrieved. As expected, the Always-Validate and No-Cache policies show much higher costs, but the policies do ensure that all served objects are up-to-date.
Table 4 shows the number of off- and on-peak bytes used for each of these policies on an average day. As expected, the two alternate policies increase the amount of network traffic during both off- and on-peak times with the Always-Validate policy increasing off-peak network traffic by 11.08MB during off-peak, 25.10MB during on-peak and 36.17MB overall in comparison to the default policy. Examination of the network traffic is important as we compare the sensitivity of different cost reduction policies to different price ratios.
The prefetching policies are invoked just before peak time begins (8:59am) in our study and attempt to validate cached objects that will expire during the upcoming on-peak time. The idea is to retrieve, during off-peak time, the new copy of any cached object that has changed. For cached objects that expire, but have not changed the idea is to validate their contents and extend their expiration time so that they will not need to validated during on-peak time. While these prefetching actions are designed to shift network traffic from on- to off-peak times, it is still possible that the off-peak retrieval or validation of a cached object will not prevent the need for validation (and possible retrieval) of the object during on-peak because the cache determines the object is relatively new and assigns it a short expiration time.
Given this general approach to prefetching, we examined a number of prefetching policies. The first policy that we tested (Original-Prefetch) was rather naive and attempted to validate, and retrieve as need be, all cached resources that expire in the upcoming on-peak period. As shown in Table 5 this policy increased the overall costs relative to the Default policy. The problem is that this policy interacts with our relatively large cache (8 GB) to prefetch many objects that have not been used recently. The act of prefetching also interacted badly with the cache replacement algorithm by making it appear that these cached objects were being used. A final problem is that our simulator is not always able to determine the status of the IMS Get request resulting in many imsUnk responses. We treat these responses pessimistically and assume they would require the retrieval of the entire contents. A more optimistic assumption would reduce the overall costs.
| Costs | Savings | Extra | Total | |||||
|---|---|---|---|---|---|---|---|---|
| Policy | IMS200 | IMS304 | IMSUnk | Miss | IMS304 | Hit | Staleness | Cost |
| Original-Prefetch | $2 | $6 | $50 | $182 | $68 | $17 | -- | $242 |
| Prefetch-1D | $2 | $6 | $22 | $183 | $68 | $17 | -- | $214 |
| Prefetch-2D | $2 | $6 | $35 | $183 | $68 | $17 | -- | $227 |
| Perfect-Prefetch | $3 | $6 | $0 | $183 | $62 | $18 | -- | $192 |
We modified the simulator to not count the prefetch as an access and limit the cached objects prefetched to those accessed in the last day (Prefetch-1D) and two-days (Prefetch-2D). As shown in Table 5 these policies reduce costs relative to the Original-Prefetch policy, but still have greater costs than the Default policy. The final prefetching policy we examined was a perfect prefetcher (Perfect-Prefetch), which was allowed to look forward in time to prefetch only those objects that were referenced in the up-coming on-peak period. While not realistic, this policy provides the potential cost reduction that could be achieved. The policy shows a small cost reduction relative to the Default policy.
To measure the sensitivity of these results to other cost ratios, we also calculated the off- and on-peak network traffic for each policy. These results, shown in Table 6, indicate that all of the prefetching policies reduce the on-peak traffic a small amount, but show large variations in the off-peak traffic increase. The last column in Table 6 shows the ``feasible'' cost ratio, which is the ratio of on-peak to off-peak traffic charges that makes the policy have the same cost as the Default policy. All policies except Perfect-Prefetch require a large cost differential to make them feasible. With a cost ratio of 3.6 at VUW we see a small cost reduction with the Perfect-Prefetch policy.
We conclude from these results that the potential of prefetching to validate and possibly retrieve cached objects is limited in reducing costs. Prefetching may more attractive in a different form or in conjunction other cache management algorithms. It would also be useful when the change characteristics of an object are known; such as when an explicit object expiration time is given. It does have the useful feature that it is not visible to end users and so does not interfere with the accustomed Web experience.
Postfetching policies delay the retrieval of objects larger than a given threshold from off-peak to on-peak time. We tested two postfetching policies: one postfetched all objects larger than 1MB (Postfetch-1M), while the other postfetched all objects larger than 512KB (Postfetch-512K). There is no change in policy for objects smaller than the threshold. As shown in Tables 7 and 8 these policies are effective in reducing the amount of on-peak traffic (and costs) with a corresponding increase in off-peak traffic. Any cost differential between on- and off-peak costs will result in a cost savings using a postfetching policy.
From a practical standpoint, this approach has an effect on users and it is more difficult to implement in a real proxy cache than it is in a simulator. The effect on users is that a small proportion (one in 5,000-10,000 in our study) of requests will be delayed. It is not clear to what extent users would be satisfied with such an approach, although if they were being directly charged for network access then we expect they would be happy to receive the cost savings.
The problem of implementing a postfetching policy is determining the size of an object before actually retrieving it. A simple, but quite expensive approach, would be to query the origin server using an HTTP HEAD request to find out the size of each object before actually retrieving it. This approach would increase the number of bytes retrieved for all objects and lengthen the amount of time to retrieve each one. Heuristics could be used to limit the overhead by only using it on suspected large objects such as ones that appear to be executables or video clips. This approach reduces the overhead, but may not identify all large objects.
The best solution and one that requires little extra overhead is to use the byte-ranges feature available in HTTP/1.1 [5] where a proxy cache can request the first chunk of bytes and headers for an object. If the object is too big the remainder of the object can be retrieved at off-peak time, otherwise retrieval proceeds as normal. In the absence of byte range requests, the proxy could just do a regular GET and terminate the connection as soon as it determines the content-length is too large. This introduces no delays in the normal case, but causes more bytes to be sent for over-sized documents before the connection can be terminated. In the simulation, we did not explicitly account for any overhead due to postfetching.
Overall, postfetching offers a simple means to provide flexible savings depending on the threshold chosen. The trade-offs are the level of inconvenience imposed on users relative to the cost savings that are realized.
The last type of policy we examined is to not validate or retrieve a cached object during on-peak time even if the object has exceeded its cache-determined expiration time. The validation of objects during off-peak time periods is not effected. This approach has the advantage of reducing on-peak network traffic at the expense of more stale objects being served to users. Four policies using this approach were tested. The first two, IMS-Max-100K and IMS-Max-10K, refused to validate any expired cache objects larger than 100KB and 10KB respectfully. The IMS-Min-10K policy refused to validate any object less than 10KB in size. The last policy, IMS-Offpeak, refused to validate any cached object during on-peak time.
The results of these four policies are shown in Tables 9 and 10. Table 9 shows that all four policies make small reductions in costs (up to 5%) in comparison to the Default policy while increasing the percentage of served objects known to be stale by a comparable amount. Table 10 shows that the policies have no impact on off-peak network traffic as we did not investigate any secondary effects of not validating during on-peak. These policies do not require a cost differential between on- and off-peak times to reduce costs so a feasible cost ratio is not applicable.
Overall, there is little appeal of reducing costs at the expense of providing users with stale objects. Users who are aware of such a policy will not know if the objects they retrieve are fresh and may be more likely to perform an explicit ``Reload'' from their browser even for objects that are actually fresh. This action will have the side-effect of increasing, rather than decreasing, network traffic.
We have proposed three classes of algorithms for caching proxies in a simple network cost model with differential charges. Prefetching, which attempts to reduce on-peak requests by updating stored objects off-peak, produced extra costs and even a close-to-ideal implementation is unlikely to produce much savings. Postfetching, which delays transferring large objects until off-peak hours, is capable of flexible savings in exchange for delayed requests, and with as little as one request in 5,000 delayed can show savings. The third of our techniques, not fetching, returns objects from the store during peak hours even if these might be out of date. It is capable of modest savings, at the expense of a comparable increase in staleness.
From a business standpoint, postfetching is the most deterministic approach for reducing costs at the expense of some user inconvenience. If network costs are accurately reflected to users then the users may actually find such a policy desirable to avoid unknowingly retrieving large objects during on-peak time. Prefetching is not a desirable approach in the general case, but could be effectively used on a limited basis for objects with known change characteristics--such as objects with explicit expiration times. Traffic shaping policies, such as presented in this work, have the potential to reduce costs in other charging models. We are currently exploring other applications of these ideas.
Craig E. Wills and Paul Thomas, © 1999. The author assigns to Southern Cross University and other educational and non-profit institutions a non-exclusive licence to use this document for personal use and in courses of instruction provided that the article is used in full and this copyright statement is reproduced. The author also grants a non-exclusive licence to Southern Cross University to publish this document in full on the World Wide Web and on CD-ROM and in printed form with the conference papers and for the document to be published on mirrors on the World Wide Web.
[ Proceedings ]