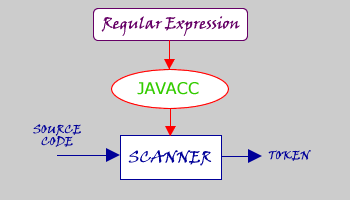
The scanner is the first part of the front
end of a compiler. The scanner scans the program source code
and divides it into proper tokens. A token is a keyword, punctuation, literal such as
number, or string. Nontokens include white space, which is often ignored
but used to separate tokens, and comments.
We can use javacc as the scanner generater to generate a scanner. JavaCC allows
us to define grammars in a fashion similar to EBNF, making it easy to translate
EBNF grammars into the JavaCC format.
Using javacc to generate scanner:
The following is cal.jj file. we shall use it to generate the scanner.
/*
* This is cal.jj file.
*/
options {
IGNORE_CASE = false;
OPTIMIZE_TOKEN_MANAGER = true;
}
PARSER_BEGIN(cal)
import java.io.*;
public class cal {
public static void main(String[] args) throws FileNotFoundException
{
if ( args.length < 1 ) {
System.out.println("Please pass in the filename for a parameter.");
System.exit(1);
}
SimpleCharStream stream = new SimpleCharStream(
new FileInputStream(args[0]),0,0);
Token temp_token = null;
calTokenManager TkMgr = new calTokenManager(stream);
do {
temp_token = TkMgr.getNextToken();
switch(temp_token.kind) {
case LPAREN: System.out.println("LPAREN: " + temp_token.image);
break;
case RPAREN: System.out.println("RPAREN: " + temp_token.image);
break;
case ADD_OP: System.out.println("ADD_OP: " + temp_token.image);
break;
case MULT_OP: System.out.println("MULT_OP: " + temp_token.image);
break;
case NUMBER: System.out.println("NUMBER: " + temp_token.image);
break;
default:
if ( temp_token.kind != EOF )
System.out.println("OTHER: " + temp_token.image);
break;
}
} while (temp_token.kind != EOF);
}
}
PARSER_END(cal)
SKIP: /* Whitespace */
{
"\t"
| "\n"
| "\r"
| " "
}
TOKEN:
{
<LPAREN: "(" >
| <RPAREN: ")" >
| <ADD_OP: "+" | "-" >
| <MULT_OP: "*" | "/" >
| <NUMBER: (["0"-"9"])+ >
}
If you have downloaded it into a /bin directory, in /bin directory the command is:
javacc cal.jj
Then you compile the generated tea.java to create a tea.class file which is your lexical analyzer:
javac cal.java
To run your generated lexer, type:
java cal inputfile
If we run our generated scanner on the test file:
test1.txt
6*(11-7)/3+100