Draw crude map. How to get from one host to another? If each link delivers
reliably then is the whole route reliable--a router may fail, limited
buffer space (may have to throw packets on the floor).
Data Link Layer--deals with machine-to-machine communication
Network Layer--lowest layer that deals with host-to-host communication,
call this end-to-end communication.
Four issues:
- interface between the host and the network (the network layer is
typically the boundary between the host and subnet)
- routing
- congestion and deadlock
- internetworking (A path may traverse different network technologies(e.g., ethernet,
point-to-point links, etc.)
The network layer should shield the transport layer from having to know
details of the underlying subnet (should not do anything different if
sending across Ethernet or across the country on the Internet).
Should the host or the subnet be responsible for the delivery of
all packets in order?
Datagram model: the host is responsible (datagrams are not guaranteed
reliably delivered)
Virtual Circuit model: subnet is responsible. Connection-oriented.
Look at Fig. 5-2.
- What type of applications want a virtual circuit? file transfer and
remote login.
- What about datagrams? When data is small compared to the setup time
(transactions).
- Datagrams can be used to implement VC's.
Two views (issue is ``does error control belong in network or
transport layer?''):
- DARPA Internet community viewpoint: The subnet is inherently
unreliable no matter how it is designed. Thus, host are forced to do
error control anyway. Given that they perform error control, why have
the network layer duplicate the same function?
The DARPA TCP/IP Internet is connectionless.
- Common carrier viewpoint: The connection oriented approach is
the right way. Users don't want complex error control protocols in
host computers. User's want reliable, trouble-free service. (X.25)
Which group dominated the ISO standardization process?
Which group has 20+ years of real implementation experience?
The network layer is responsible for routing packets from the source
to destination. The routing algorithm is the piece of
software that decides where a packet goes next (e.g., which output
line, or which node on a broadcast channel).
For connectionless networks, the routing decision is made for each
datagram. For connection-oriented networks, the decision is made
once, at circuit setup time.
The routing algorithm must deal with the following issues:
- Correctness and simplicity: networks are never taken down;
individual parts (e.g., links, routers) may fail, but the whole network
should not.
- Stability: if a link or router fails, how much time elapses before the
remaining routers recognize the topology change? (Some never do..)
- Fairness and optimality: an inherently intractable problem.
Definition of optimality usually doesn't consider fairness. Do we
want to maximize channel usage? Minimize average delay?
When we look at routing in detail, we'll consider both adaptive--those
that take current traffic and topology into consideration--and
nonadaptive algorithms.
The network layer also must deal with congestion:
- When more packets enter an area than can be processed, delays
increase and performance decreases. If the situation continues, the
subnet may have no alternative but to discard packets.
- If the delay increases, the sender may (incorrectly) retransmit,
making a bad situation even worse.
- Overall, performance degrades because the network is using (wasting)
resources processing packets that eventually get discarded.
Finally, when we consider internetworking -- connecting different
network technologies together -- one finds the same problems, only
worse:
- packets may travel through many different networks
- each network may have a different frame format
- some networks may be connectionless, other connection oriented
Routing is concerned with the question: Which line should router J
use when forwarding a packet to router K?
There are two types of algorithms:
- Adaptive algorithms use such dynamic information as
current topology, load, delay, etc. to select routes.
- In nonadaptive algorithms, routes never change once initial routes
have been selected. Also called static routing.
Obviously, adaptive algorithms are more interesting, as nonadaptive
algorithms don't even make an attempt to handle failed links.
Adaptive algorithms can be further divided in the following types:
- Isolated: each router makes its routing decisions using only the
local information it has on hand. Specifically, routers do not
even exchange information with their neighbors.
- Centralized: a centralized node makes all routing
decisions. Specifically, the centralized node has access to
global information.
- Distributed: algorithms that use a combination of local
and global information.
Flooding is a form of isolated routing. Does not select a specific
route. When a router receives a packet, it sends a copy of the packet out on
each line (except the one on which it arrived):
- To prevent packets from looping forever, each router decrements a
hop count contained in the packet header. Whenever the hopcount decrements
to zero, the router discards the packet.
- To reduce looping even further:
- Add a sequence number to each packet's header.
- Each router maintains a private sequence number. When it sends a
new packet, it copies the sequence number into the packet, and
increments its private sequence number.
- For each source router S, a router:
- keeps track of the highest sequence number seen from S.
- whenever it receives a packet from S containing a sequence
number lower than the one stored in its table, it discards the packet.
- otherwise, it updates the entry for S and forwards the
packet on
Flooding has several important uses:
- in military applications, the network must remain robust
in the face of (extreme) hostility
- sending routing updates, because updates can't rely on the
correctness of a router's routing table.
- theoretical--chooses all possible paths, so it chooses the shortest one.
In selective flooding, a router sends packets out only on
those lines in the general direction of the destination. That is, don't
send packets out on lines that clearly lead in the wrong direction.
In random walk a router selects one or more lines at random.
- equalize load (on network)
- robust
What if we ``know'' the complete topology of the network? Can look at
computing the optimal path. What if we have the following network and we
want to route a packet from node A to node G. What is the shortest path
(do not initially show distance.
Use Dijkstra's algorithm (or variation). Basic idea:
- Choose the source, and put nodes connected to source in list to
consider.
- From the list to consider choose the nearest node.
Algorithm results:
nodes list to consider
----- ----------------
(A, -, 0) B, D, E
(B, A, 2) C, D, E
(C, B, 3) D, E, H
(H, C, 4) D, E, G
(D, A, 5) E, F, G
(E, C, 6) G, F
(G, H, 7) F
(F, E, 7) -
Guaranteed to get the shortest path? How to prove? If an alternate
shorter path to a node then we would have already tried the path.
May not be a single best route between two nodes. Can use a
routing table. Can compute alternate routes between source and destination
by first computing shortest path and then removing these links.
Problem is that these routing tables are initially created and not changed.
Look at example.
Centralized--use a routing control center. Creates,
modifies, and distributes routing tables to other routers. Gathers
information from the routers.
Good: adaptive routing, relieve burden on the routers of computing tables.
Problems:
- Does not adapt quickly.
- Quicker the adaption, the more overhead it causes.
- Synchronization of updates (some routers change, but not others, send at
each other).
- If RCC crashes the network becomes stale.
- Lines near the RCC are overloaded.
Base decisions on local traffic and conditions.
Combine centralized and isolated routing.
RCC (routing control center) computes optimal paths for each router as before.
Has a parameter 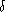 to decide if two lines are equivalent. Are
equivalent if the delay is within of each other.
to decide if two lines are equivalent. Are
equivalent if the delay is within of each other.
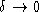 , centralized
, centralized
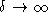 , isolated, up to the routers.
, isolated, up to the routers.
Modern networks use two dynamic (adaptive) algorithms--distance vector
routing and link state routing.
Distributed routing algorithm (Old Arpanet Routing Algorithm). routers
work together.
- Each router maintains a table (vector) giving the best known distance
to a destination and the line to use for sending there. Tables are updated
by exchanging information with neighbors.
- Each router knows the distance (cost) of reaching its neighbors (e.g. send
echo requests).
- routers periodically exchange routing tables with each of their
neighbors.
- Upon receipt of an update, for each destination in its table, a router:
- compares the metric in its local table with the metric in the
neighbor's table plus the cost of reaching that neighbor
- if the path via the neighbor has a lower cost, the router updates
its local table to forward packets to the neighbor
This algorithm was used in the original ARPANET. Unfortunately, it
suffers from the problem: good news travels quickly, bad news travels
slowly (count-to-infinity problem).
The fundamental problem with the old Arpanet algorithm is that it
continues to use ``old'' information that is invalid, even after
newer information becomes available.
The ``old'' Arpanet routing algorithm was replaced in 1979. Problems
with old algorithm included:
- High-priority routing update packets were large, adversely
affecting traffic.
- Network was too slow in adapting to congestion, too fast to
react to minor changes.
- Average queue length was used to estimate delay. This
works only if all lines have the same capacity and propagation delay,
and doesn't take into account that packets have varying sizes.
In the new algorithm:
- Each router maintains a database describing the topology and link
delays between each router. That is, each router keeps track of the
full graph of links and nodes.
- Each router periodically discovers it neighbors (sends ``hello''
message on booting) and
measures the delays across its links (echo requests--should load be taken
into account?), then
forwards that information to all other routers (link state packets)
- Updates are propagated at high priority using flooding. Updates
contain sequence numbers, and a router forwards ``new'' copies of the
packet.
Why use flooding? Because that way routing updates propagate
even when routing tables aren't quite correct. ACKs are sent to neighbors.
- Each router uses an SPF algorithm to calculate shortest paths based
on the current values in its database.
- Because each router makes its calculation using the same
information, better routing decisions are made.
Limitations of new algorithm:
- Doesn't take link capacity into consideration. A 1200 baud
link with 100 ms delay is favored over an Ethernet having an 200 ms delay.
- Doesn't scale well, as each router receives updates from all other
routers.
Today, we need to think of scaling to a system with a million
nodes and many more links! After all, 5 billion people will
(eventually) be on the network!
One of the fundamental issues regarding routing is scaling. As a
network becomes larger, the amount of information that must be propagated
increases, and the routing calculation becomes increasingly expensive.
Obviously, there are limits to how big a network can be.
Hierarchical routing is an approach that hides information from
far-away nodes, reducing the amount of information a given router needs to
perform routing:
- Divide the network into regions, with routers only knowing the
details of how to route to other routers in its region. In particular,
a router does not know about the internal topology of other regions.
Gateway is a router that knows about other regions.
- A node in each region is designated as an entry
point, and the entry point knows how to reach the entry points in all
the other regions.
- When traffic flows from A to B, it actually follows the path
A-AENTRY-BENTRY-B, where AENTRY and BENTRY are the entry points to
the respective regions.
Advantage: Scaling. Each router needs less information (table space) to
perform routing.
Disadvantage: Sub optimal routes. The average path length increases
because there may be a shorter path that bypasses the entry points,
but we don't use it.
Hierarchical routing can be extended to multilevels.
Example: telephone system:
- Area code identifies a region.
- Area code plus the first three digits identify the central
office within a specific region.
Sending a packet to all destinations simultaneously is known as
broadcasting. There are several ways to implement broadcasting:
- In broadcast networks, the implementation is trivial: designate
a special address as the ``all hosts address''.
- Send a unicast packet to each destination. However, this
approach makes poor use of resources.
- Flood packets to all nodes. Flooding generates many packets
and consumes too much bandwidth.
- Use multidestination routing: Each packet contains a list (or
bitmap) of all destinations, and when a router forwards a packet across
two or more lines, it splits the packet and divides the destination
addresses accordingly.
This approach is similar to sending unicast packets, except that we
don't send individual copies of each messages. However, the copy
operations slow down the ability of a router to process many packets.
- Use a spanning tree. If the network can be reduced to a tree
(e.g., only one path between any two pairs of routers), copy a packet to
each line of spanning tree except the one on which it arrived.
Works only if each router uses the same spanning tree.
- Reverse Path Forwarding (RPF): Use a sink tree (assume sink/source
trees are the same). When a packet arrives from router X, if the packet
arrived on a line of the sink tree leading to X, the packet is traveling
along the shortest path, so it must be the first copy we've seen. Copy the
packet to all outgoing lines.
If the packet arrives on another line, assume that the packet is a
copy -- it didn't arrive on the shortest path -- and discard it.
RPF is easy to implement and makes efficient use of bandwidth.
Source Routing--Originally used by USENET: ucbvax!decvax!mcvax!marvin
User had to know route to remote host. Used large maps of network
topology. Can be done automatically from host information stored locally.
Mobile Hosts--must get traffic to base host. Need intermediary
agents. Look at Fig 5-20. Base host uses encapsulation (tunneling) to
send packet to mobile host.
Multicast Routing--send to a group of machines. Built-in to LAN
technology for a site. Use regular IP (with forwarding and tunneling)
between sites. Compute a spanning tree of routers. See Fig 5-22