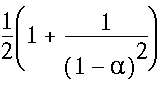Searching
Definition and terminology
Definition. Assume k1,k2,...,kn is a collection distinct keys and
R = {(k1,I1),(k2,I2),..., (kn,In)}
is a collection of records (where Ij is the information stored in record (kj,Ij)) containing those keys.
Given a key value K, the search problem is to locate a record (kj,Ij) such that K = kj.
General search approaches
- Sequential methods
- the records are considered one at a time according to a predefined ordering
- Direct access methods
- the records are accesses directly based on the value of the search key
- Indexing methods
- keys are organized into some tree structure which allows fast searching
To describe search methods we shall use the following record structure definition:
Searching arrays
The problem will be to find a record with key value K in an array
info SeqSearch (record* A, int n,key K){
info BinSearch (record* A, int n,key K){
return BinSearch(&A[0], mid , K);
BinSearch(&A[mid+1], n-mid-1, K);
- takes Q(n) time on the avg.
- Dictionary search
- if the records are sorted and the expected distribution of key values is known
- the location of the key in the key range is translated into an expected value in the array
Example. Assume that the keys are integer numbers uniformly distributed between m1 and m2.
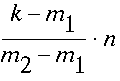
Searching lists
- the only way to search lists is sequential search
- to improve the performance of sequential search we may dynamically reorganize the list based on the frequency of accesses to the different records: move the more frequently accessed records towards the head of the list
- if p1,p2,...,pn (pi>pi+1) are the probabilities with which the records are accessed:
Example. If each record has the same probability to be searched for:

Heuristics for managing self-organizing list:
- approximate the probabilities using the number of previous accesses
- keep a access counter associated with each record
- move a record forward if the associated counter becomes greater than the one of the preceding record
- requires extra space
- changes of frequency poorly handled
- every time a record is used, move it to the front of the list
- it is efficient
- handles well changes in frequency
- hard to implement if list is represented in an array
- every time a record is used, swap it with the record preceding it (transpose)
- works well in general
- there are some patological cases
- easy to implement with arrays and linked lists
Hashing
- accessing a record in an array by mapping a key value to a position in the array
- the array storing the records is called hash table
- the function used to map keys to table entries (slots) si called hash function
- a hash function is a function defined over the set of possible key values and takes on values from the set of slots in the hash table (0 to n-1 for a table of size n)
- the range of the key values has typically much more elements than slots in the hash table
- some keys will map to the same slot (collision)
- when defining a hash function the goal is to distribute the keys uniformly over the slots
sq = sq << (sizeof(int)*8 - r) / 2;
Collision resolution
Collision resolution techniques:
- open hashing - collisions are stored outside the hash table
- closed hashing - collisions are stored in the hash table
info HashSearch (entry H[]; key K){
return SeqSearch (H[k].link, K);
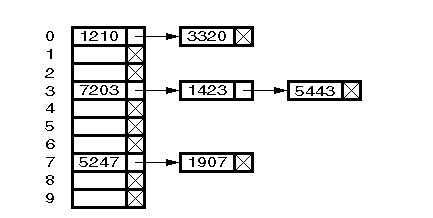
- Closed hashing
- all records are stored in the hash table
- a collision is solved by applying secondary hash functions (probing)
for ( int i = 1; H[curr].key != EMPTY ; i++){