| WARNING: Small changes to this syllabus may be made during the semester. |
|
Students will be expected to read assigned textbook chapters and
research papers,
and work on implementation/research projects that cover the different
stages of the KDD process.
In addition to being a graduate CS course,
this course can be used to satisfy:
Time: Tuesdays 6:00-8:50 pm
Prof. Carolina Ruiz TA:
Ahmedul Kabir
TEXTBOOK:
Several other books on the subject and related subjects are recommended below. Some research papers will be handed out during the semester. PREREQUISITE:GRADES:
Your final grade will reflect your own work and achievements during the course. Any type of cheating will be penalized and reported to the WPI Judicial Board in accordance with the Academic Honesty Policy. Note that this course follows the guidelines established by the WPI faculty in May 2010: "A student is expected to expend at least 56 hours of total effort for each graduate credit. This means that a student in a 3-graduate credit 14-week course is expected to expend at least 12 hours of total effort per week."Hence, please expect to have to spend at least 9 hours of work outside the classroom on this course each week. CLASS PARTICIPATIONAll students are expected to read the material assigned for each class in advance and to participate in class discussions. Also, students will take turns presenting papers and leading class discussions of assigned readings. Class participation will be taken into account when deciding students' final grades.PROJECTS, QUIZZES, AND SHOWCASESQuizzesThere will be a quiz given at the beginning of each class. Quizzes will be individual (not group) work, closed-book, closed-notes. The quiz will cover the material scheduled for that class, so that students need to study the material in depth in preparation for the lecture. No make-up quizzes will be given during the semester. No exceptions. The two lowest quiz grades will be dropped.ProjectsThis course is project-intensive. Several projects related to the data mining stages and/or techniques covered in the class will be assigned. Students will work on these projects in teams. Students will be required to provide both a written report and an oral (in-class) presentation describing their work on each of these projects. Datasets for those projects will be selected from online database repositories, or other sources.A quiz on the project material may be given in addition to or instead of the project report. Several different data mining tools will be used in this course, but the two main ones will be:
More detailed descriptions of the assignments and projects will be posted to the course webpage at the appropriate times during the semester. ShowcaseEach student needs to sign up for one of the available showcase topics. The team of students assigned to a showcase topic should identify a real-world, successful application of the data mining topic. This sucessful data mining story should be about using data mining to discover novel and useful patterns that made a difference in a certain industry or field in the past 7 years. The application domain is up to the student team (e.g., finance, sports, healthcare, science, ...). The chosen sucessful data mining story should be discussed with and approved by the professor in advance. Then the team should investigate the application in depth, and prepare and deliver a 15 minute in-class presentation describing this application in as much detail as possible, focusing on its data mining aspects. Teams will present their showcases throughout the semester, according to the showcase schedule.CLASS MAILING LISTThere are two mailing lists for this class (replace XXXX with 548 below):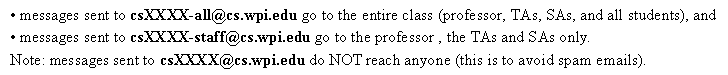
Important: For any questions about projects, quizzes, or assignments, please email the "staff" mailing list above, not just the professor. CLASS WEB PAGESThe webpages for this class are located at http://www.cs.wpi.edu/~cs548/s15/Announcements will be posted on the web pages and/or the class mailing list, and so you are urged to check your email and the class web pages frequently. WARNING:Small changes to this syllabus may be made during the course of the semester.ADDITIONAL SUGGESTED REFERENCESKnowledge Discovery and Data Mining
OTHER ONLINE RESOURCES:
|