![]()



In this project, you will build a neural network model for categorizing images. You will write a program that takes images like the hand-written numbers above and output what number the input image represents.
Your goal will be to create a model that successfully identifies the digits represented by images in MNIST with a level of accuracy as high as you can but of at least 70%, and describe and analyze your results in a written report.
Image data is provided as 28x28 matrices of integer pixel values. However, the input to the network will be a flat vector of length 28*28 = 784. You will have to flatten each matrix to be a vector, as illustrated by the toy example below:
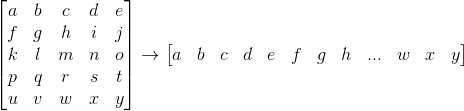
The label for each image is provided as an integer in the range of 0 to 9. However, the output of the network should be structured as a "one-hot vector" of length 10 encoded as follows:

To preprocess data, use NumPy functions like reshape for changing matrices into vectors. You can also use Keras' to_categorical function for converting label numbers into one-hot encodings.
After preprocessing, you will need to take your data and randomly split it into Training, Validation, and Test Sets. In order to create the three sets of data, use stratified sampling, so that each set maintains the same relative frequency of the ten classes.
You are given 6500 images and labels. The training set should contain ~60% of the data, the validation set should contain ~15% of the data, and the test set should contain ~25% of the data.
Example Stratified Sampling Procedure:
- Take data and separate it into 10 classes, one for each digit
- From each class:
- take 60% at random and put into the Training Set,
- take 15% at random and put into the Validation Set,
- take the remaining 25% and put into the Test Set

In Keras, Models are instantiations of the class Sequential. A Keras model template, template.py, written with the Sequential Model API is provided which can be used as starting point for building your model. The template includes a sample first input layer and output layer. You must limit yourself to "Dense" layers, which are Keras' version of traditional neural network layers. This portion of the project will involve experimentation.
Good guidelines for model creation are:
Leave the final layer as it appears in the template with a softmax activation unit.

Prior to training a model, you must specify what your loss function for the model is and what your gradient descent method is. Please use the standard categorical cross-entropy and stochastic gradient descent (`sgd') when compiling your model (as provided in the template).

You have the option of changing how many epochs to train your model for and how large your mini-batch size is. Experiment to see what works best. Also remember to include your validation data in the fit() method.

fit() returns data about your training experiment. In the template.py this is stored in the "history" variable. Use this information to construct your graph that shows how validation and training accuracy change after every epoch of training.

Use the predict() method on model to evaluate what labels your model predicts on test set. Use these and the true labels to construct your confusion matrix, like the toy example below, although you do not need to create a fancy visualization of the confusion matrix . Your matrix should have 10 rows and 10 columns.
Total Points: 120 pts