


Due Date: Sept. 14, 2017.
- Slides: Canvas Submission by 2:00 pm.
- Written report: Hand in a hardcopy by the beginning of class.
Instructions
- This is a group project.
Please do not split the project in a way that each student does only
a portion of the work. Instead each student is expected to work on
the entire project individually and then meet with the group
to clarify doubts, share findings, and combine the project solutions
into one group report.
Help or assistance from other groups, other people, or online resources is
NOT allowed.
Submit just one written report and one set of slides per group.
- If you have any questions about the project or the test, please post your questions to the Canvas discussion forum for this course. Do NOT email your question to the professor (unless your question is private and related just to your own situation). That way all students get to participate in and benefit from the discussion.
- To access the discussion forum go to Canvas, select "BCB503-CS548-F17-MASTER: KNOWLEDGE DISCOVERY AND DATA MINING" under "My Courses", and then click on "Discussions" on the left hand-side bar.
- I suggest you set up your Canvas account so that you receive email notifications when anyone in the class posts comments on the forum. For this click on the "Subscribe" button.
- High quality participation on the discussion forum (e.g., providing good answers to other students' questions) will count to your class participation grade.
- Read Chapters 1, 2, 3, and Appendix B.1 from your textbook in detail.
- You must use the
Project 1 report template
for your written report, not exceeding the page limits stated in the template
nor decreasing the font size.
- Follow the directions under
"Oral and Written Report Submission and Due Date"
below to prepare and submit your slides and written report.
-
Install the Weka system (developer version) and Python
as described in the Course Webpage.
Regarding Weka:
Regarding Python:
Problem I. Knowledge Discovery in Databases (20 points)
- (5 points) Define knowledge discovery in databases.
- (10 points) Briefly describe the steps of the knowledge discovery
in databases process.
- (5 points) Define data mining.
Base your answers on the definitions presented in class, the textbook, and the
following paper:
Fayyad, U., Piatetsky-Shapiro, G., and Smyth, P.
"From Data Mining to Knowledge Discovery in Databases".
AAAI Magazine, pp. 37-54. Fall 1996.
Problem II. Data Preprocessing (65 points)
Consider the following dataset.
% - LIFE-EXP: Life Expectancy from UN Human Development Report (2003)
% - GDPPC: GDP per capita from figure published by the CIA (2006), figure in US$.
% - AC-S-ED: Access to secondary education rating from UNESCO (2002)
% - SWL (satisfaction with life) index calculated from data published
% by New Economics Foundation (2006).
COUNTRY LIFE-EXP GDPPC AC-S-ED SWL
Switzerland, 80.5, 32.3, 99.9, '[250-275)'
Canada, 80, 34, 102.6, '[250-275)'
USA, 77.4, ?, 94.6, '[225-250)'
Germany, 78.7, 30.4, 99, '[225-250)'
Mexico, 75.1, 10, 73.4, '[225-250)'
France, 79.5, 29.9, 108.7, '[200-225)'
Thailand, 70, 8.3, 79, '[200-225)'
Brazil, 70.5, 8.4, 103.2, '[200-225)'
Japan, 82, 31.5, 102.1, '[200-225)'
India, 63.3, 3.3, 49.9, '[175-200)'
Ethiopia, 47.6, 0.9, 5.2, '[150-175)'
Russia, 65.3, 11.1, 81.9, '[125-150)'
- (5 points) Assuming that the missing value (marked with "?")
in GDPPC cannot be
ignored, discuss 3 different alternatives to fill in that missing
value. In each case, state what the selected value would be and the
advantages and disadvantages of the approach.
You may assume that the SWL attribute is the target attribute.
- (5 points) Would you keep the attribute COUNTRY into your
dataset when mining for patterns that predict the values
for the SWL attribute? Explain your answer.
- (5 points) Describe a reasonable transformation of the attribute COUNTRY
so that the number of different values for that attribute is
reduced to just 4.
- (5 points) Discretize the AC-S-ED attribute by binning it into
4 equi-width intervals using unsupervised discretization.
Perform this discretization by hand (i.e., do not use Weka).
Explain your answer.
- (5 points) Discretize the AC-S-ED attribute by binning it into
4 equi-depth (= equal-frequency) intervals using unsupervised discretization.
Perform this discretization by hand (i.e., do not use Weka).
Explain your answer.
- (10 points)
Consider the following new approach to discretizing a numeric
attribute: Given the mean and the standard deviation (sd)
of the attribute values, bin the attribute values into the following intervals:
[mean - (k+1)*sd, mean - k*sd)
for all integer values k, i.e. k = ..., -4, -3, -2, -1, 0, 1, 2, ...
Assume that the mean of the attribute AC-S-ED above is 83
and that the standard deviation sd of this attribute is 30.
Discretize AC-S-ED by hand using this new approach. Show your work.
- (30 points)
Use the supervised discretization filter in Weka (with
UseKononorenko=False) to discretize the LIFE-EXP
attribute. Describe the resulting intervals.
Find the Java code that implements this filter in the directories that contain
the Weka files. (See the instructions to find Weka's source code at the
beginning of this project assignment.)
Read the code carefully so that you can describe the algorithm followed by
this code in your own words. Follow the code by hand
to show precisely how the LIFE-EXP intervals were obtained.
Is this the same or a different procedure to the supervised discretization
procedure described in Section 2.3.6 of the texbook pp. 60-62?
Explain.
Problem III. Feature Selection (60 points)
Consider the weather.nominal.arff dataset that comes with the Weka system.
In this problem you will explain how Correlation based Feature
Selection (CFS) works on this dataset.
(See Witten's and Frank's textbook slides - Chapter 7 Slides 5-6
and also Mark A.Hall's phd thesis).
- (5 points) Apply Weka's CfsSubsetEval (available under the Select attributes tab) to this dataset (using BestFirst
as the search method, with default parameters) to determine what
attributes are selected. Include the results in your project
solutions.
- Looking at the code that implements CfsSubsetEval, as well
as its description in the textbook and in class, describe in detail
the process that it follows:
- (5 points) What's the initial (sub)set of attributes under consideration?
Is forward or backward search used?
- (25 points) Using the latice of attribute subsets below, show step by step
the process that the algorithm follows (i.e., show the search
process in detail). For this you can add print instructions to the
Weka code so that it tells you the order in which it considers the
subsets and the goodness value of each of these subsets.
Explain your answer.
- (25 points) Use the CfsSubsetEval formulas to calculate the goodness of
the "best" (sub)set of attributes considered. Show your work.
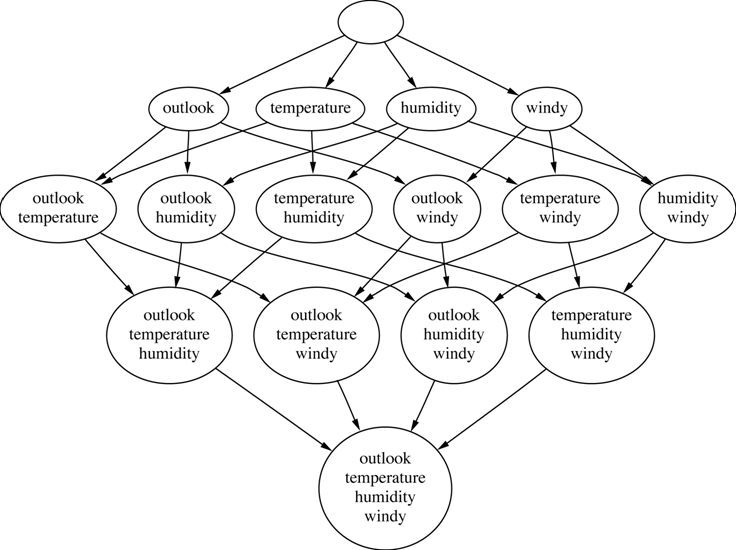
Taken from Witten's and Frank's textbook slides - Chapter 7.
Problem IV. Exploring Real Data (65 points)
Consider the
Auto MPG Data Set
available at the
UCI Machine Learning Repository.
Convert the "auto-mpg.data" dataset together with the "auto-mpg.names"
to the arff format.
- Make the attributes
mpg,
displacement,
horsepower,
weight, and
acceleration continuous;
- make the attributes
cylinders,
model-year, and
origin discrete; and
- make the attribute
car-name string.
Load this dataset into Weka by opening your arff dataset
from the "Explorer" window in Weka. Load it into Python as well.
- Dataset Exploration. (40 points)
Use Excel, Python, your own code, or Weka
to complete the following parts.
Please state in your report which tool from the above list you used
for each part.
-
(5 points)
Start by familiarizing yourself with the dataset. Carefully look at the
data directly (for this use Excel or a file editor, as well as Weka's and
Python's funcionality to explore and to visualize the data). Describe
in your report your observations about what is good about this data
(mention at least 2 different good things), and what is problematic about
this data (mention at least 2 different bad things). If appropriate,
include visualizations of those good/bad things.
-
For the horsepower attribute:
- (5 points)
Calculate the percentiles (in increments of 10, as in Table 3.2 of the
textbook, page 101), mean, median, range, and variance of the attribute.
- (5 points)
Plot a histogram of the attribute using 10 or 20 bins (you choose the
best value for the attribute). For examples, see Figures 3.7 and 3.8 in
the textbook, page 113.
-
In this part, use the discrete attributes as if they were continuous.
For the set of all attributes in the dataset except for car-name,
calculate
(1) (10 points) the covariance matrix and
(2) (10 points) the correlation matrix of these attributes.
See
notes on using Matlab and Excel to calculate these matrices.
Construct a visualization of each of these matrices (e.g., heatmap) to more easily understand them.
(5 points) If you had to remove 2 of the attributes above from the
dataset based
on these two matrices, which attributes would you remove and why?
Explain your answer.
- Dimensionality Reduction.
(10 points) Upload the entire dataset onto Weka and Python.
Apply Principal Components Analysis in Weka and separately in Python
to reduce the dimensionality of the full dataset.
In Weka, use the PrincipalComponents option from the
"Select attributes" tab.
Use parameter values: centerData=True, varianceCovered=0.95.
How many dimensions (= attributes) does the original dataset contain?
How many dimensions are obtained after PCA?
How much of the variance do they explain?
Include in your report the linear combinations that define
the first new attribute(= component) obtained.
Look at the results and
elaborate on any interesting observations you can make about the results.
- Feature Selection.
(10 points)
Use the origen attribute as the target classification attribute.
Apply Correlation Based Feature Selection (CFS)
(see Witten's and Frank's textbook slides - Chapter 7 Slides 5-6).
For this, use Weka's CfsSubsetEval available under the Select attributes tab
with default parameters. Separately, use Python for the same purpose.
Look at the results to determine which attributes were selected by this method and
elaboreate on any interesting observations you can make about the results.
- Attribute Transformation. (5 points)
Convert the car-name attribute into a discrete attribute by
changing each car-name into just the car brand
(e.g., toyota, ford, audi, ...).
Using this modified dataset, run again PCA and CFS in Weka and separately in
Python as you did above (keeping origen as the target attribute)
and report any changes you observe in the results.
Problem V. Data Integration, Data Warehousing and OLAP (50 points)
- (10 points) Describe the main differences between the
mediation approach and the data warehousing approach
for data integration.
- (Adapted from Han's and Kamber's textbook.)
Suppose that a data warehouse consists of the three dimensions
time, doctor, and patient, and the two measures
count and charge, where charge is the fee that a
doctor charges a patient for a visit.
- (5 points) Illustrate how this dataset would look as a multidimensional array
(see for instance Fig. 3.30 p. 132 of the textbook).
- (5 points) Starting with the base cuboid [day, doctor, patient],
what sequence of specific OLAP operations should be performed in order to
list the total fee collected by each doctor in 2014?
- (30 points) Consider the following relational table:
|
MODEL |
YEAR |
COLOR |
SALES |
|
Chevy |
2013 |
red |
5 |
|
Chevy |
2013 |
white |
87 |
|
Chevy |
2013 |
blue |
62 |
|
Chevy |
2014 |
red |
54 |
|
Chevy |
2014 |
white |
95 |
|
Chevy |
2014 |
blue |
49 |
|
Chevy |
2015 |
red |
31 |
|
Chevy |
2015 |
white |
54 |
|
Chevy |
2015 |
blue |
71 |
|
Ford |
2013 |
red |
64 |
|
Ford |
2013 |
white |
62 |
|
Ford |
2013 |
blue |
63 |
|
Ford |
2014 |
red |
52 |
|
Ford |
2014 |
white |
9 |
|
Ford |
2014 |
blue |
55 |
|
Ford |
2015 |
red |
27 |
|
Ford |
2015 |
white |
62 |
|
Ford |
2015 |
blue |
39 |
- (5 points) Depict the data in the relational table above as a
multidimensional cuboid, where MODEL, YEAR, and COLOR are the dimensions
and SALES is the measure.
- (5 points) Depict the result of rolling-up
MODEL from individual models to all.
- (5 points) Depict the result of drilling-down
time from YEAR to month. (Although month data is not provided above, make up
a couple of values to illustrate the drill-down operation.)
- (5 points) Depict the result of slicing for MODEL=Chevy.
- (5 points) Depict the result of dicing for MODEL=Chevy
and YEAR=2014.
- (5 points) Starting with the basic cuboid model, year, color, sales, what specific OLAP operations should one perform in order to obtain the
total number of red cars sold? Make your sequence of operations as
efficient as possible.