12.3 Run-Time Storage Management
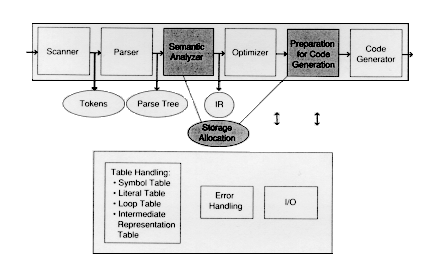
12.0 Introduction
Many compiler designers would say that a compiler is a production-quality if it implements all the features in the language, puts out good code and has good error diagnostics and recovery (Kukol, 1990). The cost here is in compiler performance, so this is not a good definition in terms of compiler performance. We will discuss features and techniques separately, pointing out their assets and liabilities. This will be especially important if "production-quality" means small and fast, and we will mention separately such features and techniques.
1. Specification Often, a compiler is designed from a language document. This document may change or may need to be changed as the project continues. Specifications of compile speed, produced code and space limitations must be considered.
2. Design Compilers may be bootstrapped from other compilers. They may use tools for many of their parts. Portability and retargetability need to be considered early in the design phase. Good interfaces are important. Key utilities such as node generators, tree-walk routines, printing utilities, etc. must be identified. These include the various tables to be used: symbol tables, type tables, label tables, most of which need to be accessed dynamically and read more than they are written to. Various intermediate representations may be designed.
3. Groundwork It is very important to build the right tools first, before building the compiler. Such tools may include a simulator if the hardware is new, since the compiler may need to be debugged before the hardware is ready. Other tools and utilities should identify and record clearly the various versions, centralize debugging and memory allocation, and identify the various compiler switches and listing utilities. Validation and testing programs should be assembled. A profiler should be created and used throughout the compiler creation life cycle. One should be prepared to measure everything.
4. Implementation Steps 1 to 3 will lay out the compiler to be implemented. Coding standards will ease the assembling of modules. Debugging must be built in. A centralized error processor saves work in the long run.
5. Maintenance A large programming language compiler may be maintained for years and involve more person-hours than any of the other phases. Again, good tools, clear interfaces and good built-in debugger facilities, as well as coordinated bug reports, can aid this process.
6. Improvement It is important to recognize early in the design process that improvements will be necessary. Techniques include a flexible framework that eases extensions.
It is also best to keep the scanner simple, letting later phases do more work. This applies, in particular, to symbol table creation. A (hashed!) name table may be created during scanning, but the true symbol table is best created during semantic analysis, when names may be resolved. For example, Ada array references have the same syntax as function calls and can be distinguished only after declarations have been processed.
Lexical analysis is a good example of software that can be fine-tuned by writing some of the routines in assembler.
Again, for a small, fast compiler, the advice may be just the opposite: syntax analysis should be tightly coupled with semantic analysis.
For small and fast, it is desirable to minimize the number of visits to each node; for example Sethi-Ullman numbering may be done as the abstract syntax tree is generated. Perhaps the object code may be emitted directly, although this will result in poorer quality code.
Aggressive optimizations are also a major source of bugs in a compiler.
Although most of this book has presumed generation of assembly language, most compiler people would maintain that generating assembler code is not a production-quality technique.
Debugger interaction with highly optimized code is difficult unless the compiler leaves a clear trail of the changes made. Standardization of object file formats has been proposed, but not accepted yet.
Small and fast compilers are required for microcomputers. They require fewer functional interfaces, fewer passes and much mixing of phases, and an avoidance of data transformations, that is, a tighter coupling. The tradeoff is a software package that is more difficult to maintain.
In addition to other machines, sometimes a compiler is to be ported from one environment or operating system to another. As UNIX became more widely used, much software was "retargeted" for this environment.
The issues in retargeting are often code generation issues: different addressing modes, different operations, a different number of registers and run-time library all need to be addressed. Memory layout may be quite different. Object code formats are different for different machines.
Another frequently used measurment is MIPS (Millions of Instructions Per Second). Without a base value to compare to, however, this becomes "Meaningless Indication of Processor Speed". For example, a one statement instruction on a non-RISC processor might require four statements on a RISC machine; it would be incorrect, if the execution speed were the same, to say that the RISC machine is four times as fast.
In addition, language-specific benchmarks are common. This is especially true of languages like Ada (Clapp et al., 1988). Measurement of the performance of specific language features is useful in specific applications.
More useful benchmark programs are those which are actually used, especially if the environment in which the compiler is to be run is known. For example, YACC is a compute-intensive program and is often run as a benchmark program. Other familiar software such as LATEX, troff, awk and various compilers are often used. Special programs such as the Sieve of Eratosthenes and Quicksort are sometimes used since they can be recorded into whatever language is being compiled.
The previous sections of these modules presume that assembly language code is to be generated by our compiler. When this is done, we need not worry about allocating space for program quantities. The assembler and other system software take care of this. Production-quality compilers (usually) do not put out assembly language code. Instead, they emit object code directly. This section does not discuss object code formats for particular machines. Instead, we discuss how the compiler facilitates the storage of information that is to take place at run-time. All of these actions could be considered as part of either the semantic analysis phase or as preparation for code generation.
Values are assigned to variables at execution time, but it is the compiler, at compile time, which performs the necessary bookkeeping so that this happens smoothly.
If we consider a program as a sequence of "unit" calls (with the main program being the first unit), then we can see immediately some of the issues. Suppose a variable, declared to be of type integer, is assigned an integer-sized space in the machine. What happens if this unit is a procedure called recursively? Clearly, there must be more than one such space allocated for such a variable.
In this section, we will proceed from simple languages (simple storage-wise!) like FORTRAN, which do not allow recursion, to languages that allow recursion, and data structures like pointers whose storage requirement change during execution.
Decisions made at compile time include where to put information and how to get it. These are the same decisions made about symbol tables (see Exercise 5), but here the information is different. For symbol tables, we are concerned about information that is known at compile time, in particular the symbol's class. Here, we are concerned about information not entirely known at compile time, such as a particular symbol's value or how many instances there will be of a variable due to recursive calls.
Storage must be allocated for user-defined data structures, variable, and constants. The compiler also facilitates procedure linkage; that is, the return address for a procedure call must be stored somewhere.
This can be though of as binding a value to a storage location and the binding can be thought of as a mapping:
Source Language ![]() Target Machine
Target Machine
Thus, although some of the later optimization phase is independent of the machine, the run-time storage algorithms are somewhat machine dependent.
Many of the compile-time decisions for run-time storage involve procedure calls. For each procedure or function, including the main program, the compiler constructs a program unit to be used at execution time. A program unit is composed of a code segment, which is the code to be executed, and an activation record, which is the information necessary to execute the code segment.
A code segment is fixed since it consists of (machine code) instructions, while the activation record information is changeable since it references the variables which are to receive values.
The information in an activation record varies according to the language being compiled. An activation record can be of a fixed or variable size.
A typical activation record contains space to record values for local data and parameters or references to such space. It also contains the return location in the code so that execution can resume correctly when the procedure finishes.
The term offset is used to describe the relative position of information in an activation record, that is, its position relative to the beginning of the activation record.
Different languages have different needs at run-time. For example, the standard version of FORTRAN permits all decisions to be made at compile-time. (It doesn't require this to be done.)
We say that FORTRAN-like languages have static storage allocation. This means that at compile-time all decisions are made about where information will reside at run-time.
Because FORTRAN typifies the issues for static storage allocation, it will be used as the example here. For FORTRAN and other languages which allow static storage allocation, the amount of storage required to hold each variable is fixed at translation time.
Such languages have no nested procedures or recursion and thus only one instance of each name (the same identifier may be used in different context, however).
In FORTRAN each procedure or function, as well as the main program and a few other program structures not discussed here, may be compiled separately and associated with an activation record that can be entirely allocated by the compiler.
Example 1 shows the skeleton of a FORTRAN program and its storage allocation.
EXAMPLE 1 Static storage example
Consider the following outline of a FORTRAN program, where statements beginning with C represent comments.
C Main Program ... Read (*,X) ... C Function ... FUNCTION ... ... C Subroutine ... SUBOUTINE ... ...
For each program unit such as the main program, a function or a subroutine (procedure), there is a code segment and an activation record. Figure 1 is a picture of what the run-time system might look like for the program skeleton of Example 1:

Figure 2 shows X's offset within the activation record:

Notice that everything except the beginning of the allocated storage is known at compile-time: the position (offset) of the activation record within the data area and even X's position (offset) within the activation record for its unit. The only decision to be made at run-time (and often made by the system linker) is where to put the entire data structure.
In static storage allocation, variables are also said to be static because their offset in the run-time system structure can be completely determined at compile time.
For languages that support recursion, it is necessary to be able to generate different data spaces since the data for each recrusive call are kept in the activation record.
Such activation records are typically kept on a stack.
When there is more than one recursive call which has not yet terminated, there will be more than one activation record, perhaps for the same code segment.
An extra piece of information must thus be stored in the activation record -- the address of the previous activation record. This pointer is called a dynamic link and points to the activation record of the calling procedure.
Languages such as Algol, Pascal, Modula, C and Ada all allow recursion and require at least the flexibility of a stack-based discipline for storage.
Example 2 shows a program and its stack of activation records when the program is executing at the point marked by the asterisks. The program is not in any particular language, but is pseudocode.

In Example 2, main's activation record contains space to store the values for the variables a and b. The activation record stacked on top of the activation record for main represents the activation record for the (first) call to P. P's parameter x has actual value a, and there is space for its value, as well as space for the local variables p1 and p2. The address of the previous activation record is stored in dynamic link.
On the other hand, the amount of storage required for each variable is know at translation time, so, like FORTRAN, the size of the activation record and a variable's offset is known at translation (compile) time. Since recursive calls require that more than one activation record for the same code segment be kept, it is not possible, as in FORTRAN, to know the offset of the activation record itself at compile-time. Variables in these languages are termed semistatic.
Block-structured languages allow units to be nested. Most commonly, it is subprograms (procedures) that are nested, but languages such as Algol and C allow a new unit to be created, and nested, merely by enclosing it with BEGIN-END, { }, or similar constructs.
The unit within which a variable is "known" and has a value is called its scope. For many languages a variable's scope includes the unit where it is defined and any contained units, but not units that contain the unit where the variable is defined.
During execution, block-structured languages cause a new complication since a value may be assigned or accessed for a variable declared in an "outer" unit. This is a problem because the activation record for the unit currently executing is not necessarily the activation record where the value is to be stored or found.
A new piece of information must be added to the activation record to facilitate this access. Pointers called static links point to the activation records of units where variables, used in the current procedure, are defined. Uplevel addressing refers to the reference in one unit of a variable defined in an outer unit. A sequence of static links is called a static chain.
Example 3 makes two changes to the program of Example 2. The variables a and b are now global to the program, and procedure P references variable a. An additional field, the static link, is shown in P's activation record.

In Example 3, the static link points from the activation records for P to that for Main since P is nested within Main.
Once again though, the actual size of the activation record is known at compile-time.
There are language constructs where neither the size of the activation record nor the position of the information within the activation record is known until the unit begins execution.
One such construct is the dynamic array construct. Here, a unit can declare an array to have dimensions that are not fixed until run-time. Example 4 shows the program from Examples 2 and 3, with such a dynamic array declaration and its activation record structure.

In Example 4, the dimensions for P3 are known when procedure P is activated (called).
Clearly, if the values for array P3 are to kept in an activation record for P3, the size of the record cannot be fixed at translation time. If a is given a value within P, as well as within Main, it is possible that the activation record for P will be a different size for each invocation.
What can be created at compile-time is space in the activation record to store the size and bounds of the array. A place containing a pointer to the beginning of the array can also be created (this is necessary if there is more than one such dynamic structure). At execution time, the record can be fully expanded to the appropriate size to contain all the values or the values can be kept somewhere else, say on a heap (described below).
Variables, like the dynamic arrays just described, are called semidynamic variables. Space for them is allocated by reserving storage in the activation record for a descriptor of the semidynamic variable. This descriptor might be a pointer to the storage area as well as the upper and lower bounds of each dimension.
At run-time the storage required for semidynamic variables is allocated. The dimension entries are entered in the descriptor, the actual size of semidynamic variable is evaluated and the activation record is expanded to include space for the variable or a call is made to the operating system for space and the descriptor pointer is set to point to the area just allocated.
There are languages that contain constructs whose values vary in size, not just as a unit is invoked, as in the previous section, but during the unit's execution. C (and other language) pointers, flexible arrays (whose bounds change during execution), strings in languages such as Snobol, and lists in Lisp are a few examples. These all require on demand storage allcoation, and such variables are called dynamic variables.
Example 5 shows the problems encountered with such constructs.
EXAMPLE 5 Dynamic variables
PROGRAM Main
GLOBAL a,b
DYNAMIC p4
PROCEDURE P (PARAMETER x)
LOCAL p1,p2
BEGIN {P}
NEW (p4)
Call P(p2) ***
END {P}
BEGIN {Main}
Call P(a)
END {Main}
In Example 5, notice that p4 is declared in Main, but not used until procedure p. Suppose that the program is executing at the point where the asterisks are shown, using the stack of activation record structure as in the previous examples. Where should space for p4's value be allocated?
P's activation record is on top of the stack. If space for p4 is allocated in P, then when P finishes, this value will go away (incorrectly). Allocation space for p4 in main is possible since the static link points to it, but it would require reshaping P's activation record, a messy solution since lots of other values (e.g., the dynamic links) would need to be adjusted.
The solution here is not to use a stack, but rather a data structure called a heap.
Heap
A heap is a block of storage within which pieces are allocated and freed in some relatively unstructured way.
Heap storage management is needed when a language allows the creation, destruction or extension of a data structure at arbitrary program points. It isimplemented by calls to the operating system to create or destory a certain amount of storage.
We will discuuss more about heaps for Lisp-like programming languages.
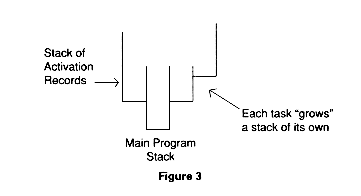
Languages such as Ada, which allow concurrent execution of program units, pose additional storage allocation problems in that each concurrently executing unit (tasks in Ada) requires a stack-like storage.
One approach is to use a heap. Still another solution is to use a data structure called a cactus stack.
Lisp is a programming language whose primary data struture is a list. Druing execution, lists can grow and shrink in size and thus are implemented using a heap data structure.
Although we refer explicitly to Lisp here, we could equally well be discussing Snobol, a string-oriented language, or any other language that requires data to be created and destroyed during program execution.
In Lisp-like languages, a new element may be added to an existing list structure at any point, requiring storage to be allocated. A heap pointer, say, Hp, is set to point to the next free element on the heap. As storage is allocated, this pointer is continually updated. Calls to operating system routines manage this allotment.
Certainly, if storage is continually allocated and not recovered, the system may soon find itself out of space. There are two ways of recovering space:explicitly and garbage collection, a general technique used in operation system. We will discuss these two as they relate to Lisp.
Explicit Return of Stroage
Consider the list 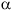 in Figure 4, where each element contains two fields: the information
field and a field containing a pointer to the next element of the list. The element
, itself, points to (contains the address of) the first element in the list.
in Figure 4, where each element contains two fields: the information
field and a field containing a pointer to the next element of the list. The element
, itself, points to (contains the address of) the first element in the list.

In LISP, an operator called (for historical reasons) cdr, given a pointer to one element in a list, returns a pointer to the next element on the list.
The question is whether or not cdr should cause the pointer to be returned to the
heap.
If is the only pointer and cdr doesn't return it to the heap, then it becomes
"garbage" (a technical term whose meaning should be clear!).
However, if cdr does return it and other pointers (shown as "?" in the picture
above) do exist, then they become dangling references; they no longer point to
because it no longer exists.
Unfortunately, it is difficult to know, although some creative (and time consuming!) bookkeeping could keep track. The alternative is to allow garbage to be created and periodically to "clean up"- a method called garbage collection.
Garbage Collection
When the garbage collection method is used, garbage is allowed to be created. Thus, there is no dangling reference problem.
When the heap becomes exhausted (empty), a garbage collection mechanism is invoked to identify and recover the garbage. The following describes a garbage collection algorithm. It presumes that each element in the system has an extra bit called a "garbage collection bit" initially set to "on" for all elements.
Algorithm
Garbage Collection
Step 1. Mark "active" elements, that is, follow all active pointers, turning "off" of the garbage collection bits for these active elements.
Step 2. Collect garbage elements, that is, perform a simple sequential scan to find elements with garbage bit on and return them to the heap.
The previous sections have discussed storage allocation "in the large", that is , the general activation record mechanisms necessary to facilitate assignment of data to variables.
Here, we disucss one issue "in the small", that of computing the offset for an element in an array. Other data structures such as records can be dealt with similarly (see Exercise 1).
Computation of Array Offsets
Array references can be simple, such as
A[I]
or complex, such as
A[I - 2, C[U]]
In either case the variables can be used in an equation that can be set up (but not evaluated) at compile-time.
We will do this first for an array whose first element is assumed to be at A[1,1,1,...,1].
That is, given an array declaration
A: ARRAY [d1, d2, ... dk] OF some type
what is the address of
A[i1, i2, ... ik]?
It is easiest to think of this for the one- or two-dimensional case. For two dimensions, what is the offset for
A[i1,i2], given a declaration A: ARRAY[d1, d2] OF some type
By offset, we mean the distance from the base (beginning) of the array which we will call base (A).
To reach A[i1, i2] from base (A), one must traverse all the elements in rows 1 through i1 - 1 plus all the columns up to i2 in row i1. There are d2 elements in each of the i1 rows; thus, A[i1, i2]'s offset is:
(i1 - 1) * d2 + i2
The absolute address is
base (A) + (i1 - 1) * d2 + i2
For k-dimensions that address is:
base (A) + ((((i1 - 1) * d2 + (i2 - 1)) * d3 + (i3 - 1))
* d4 + ...) * dk + ik
or
base (A) + (i1 - 1) * d2d3...dk + (i2 - 1) * d3...dk + ...
+ (ik-1 - 1) * dk + ik
The second way is better for the optimization phase because the sum of indices is multiplied by constants, and these constants can be computed at compile time via constant computation and constant propagation.
In the next section, we discuss an implementation method using attribute grammars. This was touched upon in Module 6.
Computation of Array Offsets Using Attribute Grammars
Consider the following grammar for array references:
NameId Name
We want to be able to attach attributes and semantic functions to these.
Example 6 shows a three-dimensional example and attributes Dims, NDim and Offset. Dims is an inherited attribute. It consults the symbol table at the node for the array name (A here) and fetches the values d1, d2, and d3 which are stored there. These are handed down the tree and used in the computation of Offset, which is a synthesized attribute. Attribute NDim is a counter that counts the number of dimensions, presumably for error checking.
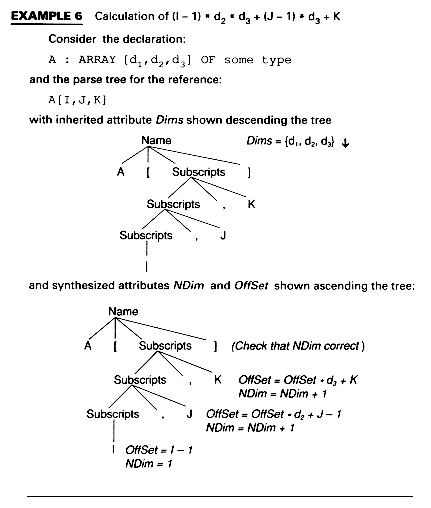
Exercise 3 asks the reader to write the semantic functions to compute the values for these attributes, while Exercise 4 suggests another way to write the grammar that will allow the attributes to be evaluated in one pass up the tree. This is material repeated from Module 6, so the reader may wish to refer back to that chapter.
The exercise ask the reader to consider other compile-time structures which have storage needs such as record.
In sections 12.5 and , 12.6 we describe a few compilers to see how a compiler in the real world has made the compromises described in this chapter (as well as other compromises).
Many of the first language processors operated incrementally. A programmer typed a line and it was processed right through to execution. BASIC interpreters were (and are) designed for this model. More complex language constructs and needs for efficient translation lead to compilers and the decrease of these early incremental techniques.
Modern programming language environments, with syntax-directed editors and complex optimizations, have discovered a new need for incremental translation techniques. In general, it is wasteful to recompile an entire program when a small change has been made.
The high-level techniques described in Sections 9.7 and 10.5 are amenable to incremental processing. Many Ada compilers also take advantage of recently developed techniques for incremental compilation. We will divide the incremental discussion here into front-end and back-end issues.
When programs consist of a number of separately compiled units, a unit may need to be recompiled, or partially recompiled, when a change is made to that unit or a change is made to to any unit in which the unit's identifiers are declared. A clever compiler can discover when a compilation is redundant.
The Turbo Pascal compilers are examples of the compilers whose needs are described by the small but fast compiler techniques of Section 12.2.6.
Turbo Pascal supports the full range of standard Pascal as well as a few features of its own such as a byte data type, special array types, additional arithmetic operators, built-in strings and much more.
It is small because it was originally designed for the 86-family of computers with limited physical memory. In fact, it is designed to run in the absence of a hard disk if necessary.
Turbo Pascal is fast, processing more than 30,000 lines/minute on a two MIP (mil- lions of hardware instructions per minute) machine. This translates to 15,000 lines/minute/MIP.
Memory management must deal with the 86-family's segmented architecture (see Lemone, 1986) and with limited operating services. Turbo compilers emphasize environments and come with their own editor and debugger.
Turbo compilers do not follow the textbook structure of separate phases and modular design which would enhance portability, reliability and maintainability, although
they are quite reliable and have been ported to other machines. Such designs would be too large and too slow.
In the original Turbo Pascal, the scanner consumes about 25% of the compiler while the parser takes 30 40% and 30-40% is for code generation. The parser is recursive descent (thus contradicting the belief that recursive descent is not the method of choice for "serious" compilers). The semantic analysis phase is mixed with parsing and does not change to an intermediate representation.
Turbo Pascal has fewer functional interfaces, eliminates many passes and mixes phases.
Earlier versions of Turbo Pascal used a linear symbol table structure. Later versions use a more efficient structure.
Live variable analysis is limited to fewer than 16 variables on 16-bit versions of the 86-family and to 32 bits on the 32-bit versions, so that bit vectors may be used (see Chapter 8). Other optimizations include constant propagation, which is per- formed "on the fly" as the tree is built.
Turbo Pascal does not do error recovery. Because the environment is integrated, the user is put back into the editor when an error is encountered.
Because the original Turbo Pascal is written for the 86-family, whose architecture presents "unique problems", code generation must be aware of special purpose registers. When Turbo Pascal was ported to the 68000, the code generator was reduced by half.
To complete the non-textbook approach: the original Turbo Pascal was written entirely in assembler!
There are many Ada compilers. Rather than describing one, some problems and features, in general, will be mentioned. Many Ada compilers are designed for special architectures, so much of the material in Module 12 applies to Ada compilers. The reference at the end of the chapter include more detailed reports on Ada compiler technology (see, in particular, Ganapathi and Mendal, 1989).
Ada is a complex language with difficult to implement constructs. It was designed by a committee over a period of years. An Ada compiler is not deemed official unless it passes a validation suite which was designed at the same time as the language was designed.
Ada is designed for separate compilation, that is, it is designed so that modules, called packages, may be compiled separately and then linked. Incremental compilation is supported by most Ada compilers in the recompilation of packages. Many compilers support incremental recompilation at the semantic analysis phase when a change is "local".
On multiprocessor systems, compiler phases, which are not dependent upon one another, may be compiled in parallel.
Most Ada systems consist of an environment of a syntax-directed and semantics- directed editors, a debugger, and other tools. The compiler is but one of the tools
Ada is designed with its own high-level intermediate representation, Diana (Descriptive Intermediate Attributed Notation for Ada), and a lower level IR, called CGIR .
Type checking in Ada is an important part of the semantic analysis phase. Ada allows overloading of many constructs including functions and procedures (see Module 2). Ada also requires strong typing, that is, the type of a name must be resolved at compile time.
Optimization is especially important in Ada compilers since one of Ada's stated applications is in embedded systems, systems which often must run in real-time. Many optimizations are machine dependent; RISC machines in particular (see Module 13) present opportunities for optimizations.
A compiler is a large programming project, but a highly visible one, within a computer system. Like many large pieces of software, good tools and good design facilitate the entire process.
This module has also discussed data structures and techniques used by compilers to facilitate decisions to be made at run-time. Many of the data structures for run-time structures are the same as those for symbol tables; we could easily use a stack symbol table structure for block-structured languages. Language features such as recursion, block structure and dynamic variables influence the type of run-time system required.
If a program is to be translated to assembly language, the assembler's run-time system takes care of many of the issues discussed here.
A translated program requires space for the code as wel1 as for the static data, and any space needed for the stack or heap data.
Real-life compilers often make compromises with the textbook descriptions as illustrated by Turbo Pascal.
In Module 13, we will discuss specific compiler details for compilers for special architectures such as RISC machines.