Chapter 6 CDK begins with discussion on operating system structure which we
discussed previously.
Also talks about naming a little and virtual memory with external pagers.
Not the focus of this material.
Goes on to talk about processes and threads. Fig 6.4 is interesting
with regard to terminology:
| Distributed OS kernel |
Thread name |
Exec. Env. Name |
| Amoeba |
Thread |
Process |
| Chorus |
Thread |
Actor |
| Mach |
Thread |
Task |
| V System |
Process |
Team |
| Unix |
- |
Process |
| Linux |
Shared-memory Task |
Task |
Threads vs. Processes
- threads are cheaper to create
- switching between threads in same process is much cheaper
- easier sharing of resources between threads
- lack of protection between threads within a process
Also called lightweight processes. Contain an execution state within
a shared address space.
Threads are natural to use for a server handling requests. Each request
can be handled by a thread.
Synchronization primitives:
- mutex
- condition variables. Can unlock mutex, wait on a condition and then
get it back when the condition occurs.
Scheduling:
Can use either preemptive or non-preemptive scheduling. Why
one over the other? Same issue as with process scheduling? Closer
coordination. Preemptive scheduling does not seem as crucial.
User vs. Kernel threads. Fig 12-8 (from perspective of user threads):
- can implement on a system not supporting kernel threads
- fast creation of threads (kernel not involved)
- fast switching between threads (kernel not involved)
- customized scheduling algorithm
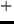
- must have jackets around system calls that may block
- no clock interrupts for time slicing
- use threads when there are many system calls, not much more work
to switch threads in the kernel.
- do not gain on a multiprocessor.
- for all threads, worry about non-reentrant code (errno).
Specific examples of calls in CDK text.
Can show both theoretically and practically that many idle nodes exist at
any one time. Look at Fig 11.1 and 11.2 from Singhal.
What is performance we are trying to optimize?
- response time
- throughput (jobs through system)
Issues:
- load measure--resource queue lengths. Most common is CPU queue
length. V-System uses the CPU utilization. Other measures--memory, file,
display.
- Static/Dynamic, Adaptive then changes it how operates (may quit
collecting status, or collect it less often).
- Load Balancing/Load Sharing. Higher overhead for load balancing
because it tries to keep the loads equal (as opposed to just keeping
processors busy).
- Preemptive/Non-preemptive transfers. Migration during execution
implies passing state.
- transfer policy--should a task be transferred? Usually based on a
threshold.
- selection policy--which task to transfer. Next task, tasks that
will take a long time (to justify migration costs).
- location policy--which node to transfer to. Use polling,
multicasting or broadcasting.
- information policy--when to collect system state information
- demand-driven--only collect information when needed.
- periodic--non-adaptive
- state-change-driven--only when state has changed
- Sender-Initiated--ELZ is a good example.
- Receiver-Initiated--Idle nodes search out for tasks, leads to
preemptive transfers since tasks often have received some amount of
service.
- Symmetrically-Initiated--do both at once. Can have an upper and
lower threshold. Each node tries to keep its load within an
acceptable range. Does adjust its threshold.
Look at Singhal Fig 11.6
- Adaptive Algorithms--can change thresholds, may want to do for
sender-initiated at high loads. Keep track of responses from the probes so
a cache of receivers, senders, and oks are kept at each node.
co-scheduling or gang scheduling to get processes that are cooperating to
run at the same time.
- scalability--how large can the mechanism scale?
- location transparency--hide distributed nature
- determinism--works the same in all locations
- preemption--be able to move away from workstations that are no
longer idle.
- heterogeneity--should know particular hardware of machines.
State transfer and then unfreeze
Examine ELZ paper.
Look at memory management on a multiprocessor and a distributed system.
Two models
- Shared memory, uniform access
Look at cache affinity paper for processor scheduling.
- Non-uniform memory.
Cache affinity for task scheduling in server. Slides:
http://www.cs.wpi.edu/~cs535/s03/larus:usenix02/