To get your participation credit, make sure you
upload your Definitions file to turnin before you leave the lab!
(This work will not be graded---full credit just for submitting.)
This lab is designed to help you practice programming with trees while teaching you a new data structure that is used in many areas of computing.
You need to use Intermediate Student with Lambda language level for this lab!
Although basic boolean expressions (using and/or/not) are straightforward, they are extraordinarily useful in computing and computer science. For example, hardware circuits are built from devices for these operations (plus simple memory units), while configuration tools for selecting features when you order a bicycle or laptop use boolean formulas to capture sets of features that must or cannot be used in the same product. In both cases, we often need to check whether two formulas are logically equivalent or what the differences are between them (such as if we try to optimize the circuit or rearrange the configuration options)--multi-million dollar companies produce tools for this problem in each of these domains. This lab looks at both naive and state-of-the-art data structures for manipulating boolean formulas.
We'll use the following data definition for boolean formulas, where symbols are used to name variables:
;; A formula is one of ;; - boolean ;; - symbol ;; - (make-notf formula) ;; - (make-andf formula formula) ;; - (make-orf formula formula) (define-struct notf (fmla)) (define-struct andf (fmla1 fmla2)) (define-struct orf (fmla1 fmla2))We are using
andf and orf to avoid errors
from reusing the built-in and and or keywords.
For example, the formula "hard-disk AND [track-pad OR track-point]" would be captured as
(define laptop-conf (make-andf 'hard-disk (make-orf 'track-point 'track-pad)))
Put your name in a comment at the top of the Definitions area.
One basic operation on formulas is checking whether they
evaluate to true under a particular assignment of boolean values to
the variables (for example: given the set of features chosen, do they
violate any constraints on feature combinations as captured by the
formula). Write a function eval-formula that consumes a
formula and a list of symbols (for the variables that have been set to
true) and produces a boolean indicating whether the formula is true
or false under the given setting of true variables.
For example, (eval-formula laptop-conf (list
'track-point)) should return false, whereas (eval-formula
laptop-conf (list 'hard-disk 'track-point)) should return true.
formulas-equiv? that consumes two
formulas and a list of all the variable names (symbols) appearing in
the formulas; the function produces a boolean indicating whether the
two formulas produce the same answer on every possible subset of those
variables set to true. Assume the two formulas have the same set of
variables.
Hint 1: Write a helper to take a list of symbols and generate all
possible subsets of that list. For example, the set of all subsets of
(list 'a 'b) consists of empty, (list 'a), (list 'b), and (list 'a 'b).
Hint 2: Racket includes a function andmap that
consumes a function from X to boolean and a list[X] and determines
whether the function is true for every element in the list. Use this
function if you wish.
Everybody should get at least this far, and at least get started on the next question.
Real-world formulas (particularly in hardware) involve thousands if not millions of variables. At that scale, running through all the combinations of values to check equivalence is too expensive. Instead, we'd like a way to compare the formulas without testing them for each combination of variable values. To do this, we use a different representation of formulas called a binary-decision diagram (or BDD). A BDD is a binary tree in which each internal node is labeled with a variable: one outgoing edge gives the formula for when the variable is false and the other outgoing edge gives the formula for when the variable is true. Leaves are labeled with just booleans. For example, our laptop formula is represented with the following BDD:
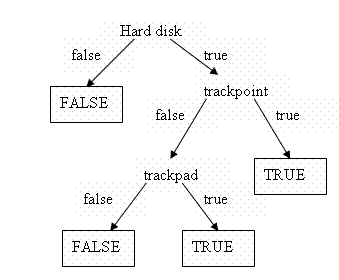
BDDs are built using some fixed order on the variables in the formula (in this case, hard-disk, trackpoint, trackpad, with the order corresponding to the levels in the tree). If both the true and false branches from a node lead to the same formula, the variable for that node gets skipped (which is why trackpoint and trackpad do not appear in the false subtree for the harddisk node). In addition, if two subtrees have the same contents, we use only a single copy of the subtree (for efficiency).
Use the following data definition for BDDs:
;; A bdd is either ;; - boolean, or ;; - (make-bddnode symbol bdd bdd) (define-struct bddnode (var whenfalse whentrue))Write the BDD in the picture above using this data definition to make sure you understand the data definition.
Write a function eval-bdd that consumes a bdd and
a list of symbols (for the variables that have been assigned true) and
produces a boolean indicating whether the formula is true or false
under that set of true variables.
If you represent a formula as a BDD, the formula and the BDD
should have the same value for every possible choice of true
variables. Write a function formula-bdd-equiv? that
consumes a formula, a bdd, and a list of symbols (variable names) and
produces a boolean indicating whether the formula and bdd compute the
same answer for every subset of variables set to true.
The whole point of switching to BDDs was to optimize
equivalence checking. Write a function bdd-equiv? that
consumes two BDDs (constructed with the same variable order) and
produces a boolean indicating whether the two BDDs compute the same
function. You can check this by walking the trees for the two BDDs
starting from the roots, checking that the variable names at the
current nodes are identical, the two whenfalse subtrees are equivalent
and the two whentrue subtrees are equivalent.
If you get this far, choose from the following problems, depending on the level of challenge you want.
[Normal] When two BDDs aren't equivalent, modern tools produce
examples of truth assignments to variables on which the formulas yield
different answers. For example, given the BDDs for "x and y" and "x
or y" one possible difference is the list (list x), which
says that if x is true and y false (implicit, by not being in the
list), the two BDDs given different answers. Write a function
find-diff that consumes two BDDs and produces a list of
variable names such that if those vars are set to true (and all others
false), the two BDDs will produce different answers.
[one-star challenge] Rather than create BDDs by hand, as you have done until this point, tools convert from formulas to BDDs automatically. This problem has you write the converter.
Use your existing functions to help test your work on this problem. Consider writing one function to do the work of the bdd-and and bdd-or operations, passing in a function to handle the nodes with booleans.
[two-star challenge] BDDs are efficient because they keep only
one copy of each subtree. Write a function condense that
consumes a BDD possibly containing duplicate subtrees and produces a
BDD that has at most one copy of each subtree (using pointers to the
same subtree in memory for shared subtrees).
For more information on BDDs, see the wikipedia entry. BDDs revolutionized hardware analysis back in the 1980s.