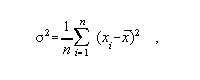
Due date: February 03, 2003, by 11:59pm
An important feature of multi-person audioconference is detecting speech in the presence of background noise. This problem, often called speech detection, boils down to detecting the beginning and ending of a section of speech, called a talk-spurt. By removing silent periods between talk-spurts, network bandwidth and host processing can be greatly reduced. Moreover, end-host applications often use the times between talk-spurts to reset their delay buffers.
Rabiner and Sambur [RS75] describe an algorithm which locates the endpoints of a talk-spurt based on an algorithm that uses the zero crossing rate and the energy. Their algorithm is relatively simple and accurate and has low CPU overhead.
You will implement the Rabiner and Sambur algorithm in an application that records speech from a microphone. Your program will store two versions of the sound, one with all the sound recorded and the other with sound removed. In addition, your program will store a third file of data in text format, allowing you to plot the captured audio signal, energy computations and zero level crossings.
You will write a program, called record, that records
sound from the microphone until the user presses ctrl-c
and exits. Your program will produce 3 files as output:
sound.all will contain the
audio data recorded with all the sound, including the silence
sound.speech will contain the
audio data recorded without silence
sound.data will contain three columns
of text-based data: audio data, energy, zero crossings
with the values separated by tabs. For example,
a typical data file might look like:
128 10 3
127 12 4
127 20 3
...
You should configure the sound device to capture audio at typical voice quality rates: 8000 samples/second, with 8 bits per sample with one channel (mono, not stereo).
Read the Rabiner and Sambur paper carefully for details on the algorithm. You should follow it closely. Note, however, that they use a 10kHz sample frequency whereas you'll use a 8kHz sample frequency, so adjust your algorithm appropriately.
You are free to add command line options or other features that you'd like as long as the base functionality as indicated in this writeup is present.
You can record a fixed chunk of audio data on which to detect silence. For example, you can record sound in 100ms intervals and then apply the speech detection algorithm to it.
Variance is the mean of the squares of the differences between the respective samples and their mean:
where: n is the number of samples; xi is
the value of sample i; x_bar is the mean of the
samples, and sigma2 is the variance. The square
root of the variance, sigma, is the standard deviation.
Remember, in Linux, you'll need a -lm compile time option
to link in the math library for using sqrt().
You can use a plotting program to help analyze some of the data you
have. I'd recommend gnuplot. It has a variety of output
and a nice command line interface. You can check out http://www.gnuplot.org/ for a good
guide.
Here is some coarse pseudo-code for the application that may be helpful:
open sound device
set up sound device parameters
record silence
set algorithm parameters
while (1)
record sound
compute energy
compute zero crossings
search for beginning/end of speech
write data to file
write sound to file
if speech, write speech to file
end while
You might look at the slides for this project (ppt, pdf) and [RS75] (ppt, pdf).
You may do your implementation in Linux or Windows. This sub-section has some Windows-specific hints.
If you have not used Microsoft Visual C++, you might want to try this basic tutorial. (but be warned that it is for version 5.0). Or, you could try text tutorial for version 6.0. The Microsoft Developer's Network has more elaborate tutorials you can try.
To use the sound device, you first create a variable of type WAVEFORMATEX. WAVEFORMATEX is a structure with fields necessary for setting up the sound parameters:
To read from the sound device (ie- the microphone), you make the
system call waveInOpen(), passing in a device handle
(HWAVEIN), the device number (1 in the Movie Lab), the WAVEFORMATEX
structure above and a callback function. The callback function gets
invoked when the sound device has a sample of audio.
As the sound device records information, it needs to be put into a buffer large enough to store the sound chunk (say, 500ms) you wish to record. You need to create more than one buffer so that the device can read ahead. The buffers are of type LPWAVEHDR. The LPWAVEHDR structure contains lpData, which will record the raw data samples, and dwBufferLength which needs to be set to nBlockAlign (above) times the length (in bytes) of the sound chunk you wish to read from the device.
Once prepared, the LPWAVEHDR buffers are then given one at a time
to the sound device via the waveInAddBuffer() syste call,
Giving it the device, the buffer (LPWAVEHDR) and the size of a
LPWAVEHDR variable. When the callback function is invoked, the sound
data itself will be in the lpData field of the buffer. That data can
then be analyzed for speech and written to a file or the audio device
(writing to the audio device is very similar to reading from it) or
whatever. Another buffer then needs to be added to the audio device
via waveInAddBuffer(), again.
Here are some of the header files you will probably find useful:
#include <windows.h> #include <stdio.h> #include <stdlib.h> #include <mmsystem.h> #include <winbase.h> #include <memory.h> #include <string.h> #include <signal.h> extern "C"
Here are some data types you will probably use:
HWAVEOUT /* for writing to an audio device */ HWAVEIN /* for reading from the audio device */ WAVEFORMATEX /* sound format structure */ LPWAVEHDR /* buffer for reading/writing to device */ MMRESULT /* result type returned from wave system calls */
You'll need to link in the library winmm.lib in order
to properly reference the multimedia system calls.
See the online documentation from Visual C++ for more information.
You may do your implementation in Linux or Windows. This sub-section has some Linux-specific hints.
Audio in Linux is typically accessed through the device
/dev/dsp. You can open this device for reading and
writing as you would a normal file (ie- open("/dev/dsp",
O_RDWR). Reading from the device (ie- read() will
record sound while writing (ie- write()) to the device
will play sound.
You use the ioctl() function to change the device
settings (do a man ioctl for more information). The first
parameter is the sound device file descriptor, the second is the
parameter you want to control and the third is a pointer to a variable
containing the value. For example, the code:
fd = open("/dev/dsp", O_RDWR);
arg = 8;
ioctl(fd, SOUND_PCM_WRITE_BITS, &arg);
will set the samples size to 8 bits. The parameters
you will be interested in are:
SOUND_PCM_WRITE_BITS to set
the number of bits per sample
SOUND_PCM_WRITE_CHANNELS to set
the sound device to be mono or stereo
SOUND_PCM_WRITE_RATE to
set the sample/playback rate
Only one process at a time can have the audio device
(/dev/dsp) open. If you get a "permission denied" error
when you try to read or write to the audio device, it is likely
because another process has it open.
Use a makefile to make compiling easier. Here is a sample (note, the indented lines must be a tab and not spaces):
#
# Makefile for record
#
CC= gcc
all: record
record: record.c
$(CC) -o record record.c -lm
clean:
/bin/rm -rf core record
You must turn in all source code used in your project, including header files. Please include the project files required for building your code. Have a README file with any special instructions or platform requirements for running your application.
You will use the online turnin program
(/cs/bin/turnin) to submit your files:
Package up (with pkzip) your files, for example:
mkdir proj1 copy * proj1 /* copy all your files to submit to proj1 directory */ pkzip proj1.zip proj1
Copy the proj1.zip to your account on
the ccc machines.
Run:
/cs/bin/turnin submit cs525z proj1 proj1.zip
to submit your files.
[RS75] L. Rabiner and M. Sambur. An Algorithm for Determining the Endpoints of Isolated Utterances, The Bell System Technical Journal, Vol. 54, No. 2, Feb. 1975, pages 297-315.
 Return
to the Multimedia Networking Home Page
Return
to the Multimedia Networking Home Page
Send all project questions to the TA mailing list: cs525z_ta@cs.wpi.edu.