Java-Based Load Distribution on the World Wide Web
Brian Brennan
Southern New England Telecommunications
545 Long Wharf Drive, 4th Floor
New Haven, CT 06511 USA
Chris Brennan
Digital Equipment Corporation
129 Parker St.
Maynard, MA 01754 USA
David Finkel and Craig E. Wills
Department of Computer Science
Worcester Polytechnic Institute
Worcester, MA 01609 USA
Corresponding Author: David Finkel
Department of Computer Science
Worcester Polytechnic Institute
Worcester, MA 01609 USA
Telephone: +1 (508) 831-5416
Fax: +1 (508) 831-5776
E-mail: dfinkel@cs.wpi.edu
Abstract
This paper describes a system for using the World-Wide Web to distribute computational workload to multiple hosts on the Web. A programmer with a computation to distribute registers it with a Web server. An idle host uses this server to identify available computations and downloads a Java class to perform the computation. The paper describes the programs written to carry out the load distribution and our experience in using it.
The goal of this project was to develop methods for distributing computational workload to idle machines on the Internet. The system is implemented in Java, and provides a framework for an application programmer to develop Java classes to permit multiple machines to download and execute portions of a computation. Using this system, the programmers could potentially have a large number of machines executing their applications.
There have been a large number of research efforts directed to load balancing in a distributed system [5, 7]. These research efforts show that distributing load to idle machines leads to improved overall performance. Most of these efforts involved distributing workload in a local area network, across machines of identical architecture.
The Charlotte project [1] provides a processing environment based on the World Wide Web. Charlotte implements a shared memory and inter-process communication paradigm currently used in multiple processor machines. Charlotte gave standard Java applets the ability to access variables on the host computer as if they were their own. Thus Charlotte uses the medium of the World Wide Web to create a parallel programming environment.
The current project uses Java to provide a parallel programming environment suitable for coarse-grain parallel computations. Java classes are downloaded from a server to a machine on the Web, and the results of the computation are returned to the server. Additional details of our system can be found in [2].
The remainder of the paper describes the architecture and implementation of the load distribution system, and our experience in using it. Finally, the paper presents some ideas for extension of this work in future implementations.
2.1 Implementation Architecture
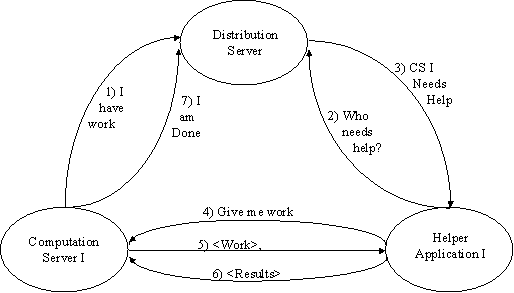
There are three main components to our load distributing system: the Helper Application, the Distribution Server, and the Computation Server. The Helper Application is a Java application that runs on a computer on the Internet. When the computer is idle, the Helper Application contacts the Distribution Server to locate a computation to be performed. The Helper Application then connects to a Computation Server with work to distribute, downloads a Java class to execute, executes it, and returns the result to the Computation Server.
The Helper Application, the Distribution Server, and the Computation Server have all been implemented as part of this project. An application programmer who wishes to prepare an application for distribution must prepare a Java class to perform the computation. Predetermined methods must be implemented in this class; these are used by the Helper Application to download the arguments to use in the computation, to execute the computation, and to return the result to the Computation Server. The application programmer must also register the computation with the Distribution Server, so that Helper Applications can locate the Computation Server.
The Helper Application has been written as a Java application [3, 6]. Java programs are either applets or applications. Java applets are designed to be downloaded by Web browsers and execute within the browser. Java applets have security restrictions so that they cannot damage the computer on which they are running. For example, Java applets cannot access local files on the machine on which they are running, and cannot make network connections to sites other than the one from which they have been downloaded. Applications, on the other hand, do not have these restrictions, and can perform the usual functions of an application program. The restriction on network connections required that the Helper Application be written as a Java application instead of an applet; the Helper Application needs to be able to create network connections to both the Distribution Server and the Computation Server. In order to provide the kind of security available in executing an applet, we implemented a security model in the Helper Application.
The following describe the main points of the operation of the Helper Application:
In order to use a computer without disturbing its owner, we set the default Java priority of each computation class to 2 on a scale of 1 (low) to 10 (high). Embedded in the helper application we have placed a safeguard to make sure that the class does not set itself above a priority of 4. Because a job is capped at a priority of 4, it will never interfere with the normal operations of the helper computer.
Once a computer is free to do work, the Helper Application contacts the Distribution Server and downloads a list of running computations. Currently, the computation choice is completely random, but in the future a more selective scheduling algorithm can be added to accommodate priority computations.
After the helper finds a computation to help, it contacts the appropriate Computation Server and asks for work using a TCP connection to the server. The server replies with an identification number and a distributable class name, or a message saying that there is no more work. The Helper Application checks to see if it has already downloaded the class from this server. If it has not, it requests the Java byte-code of the class. The distributable class is written by the developer to contain all of the application-specific implementations of the job distribution. The class must inherit from the class Distributable, which was developed as part of this project, and must have methods getArgs, run, and sendResults as described below.
Once the Helper Application has the class description, it instantiates the class into an object and calls the object’s getArgs method, passing it the streams associated with the TCP connection. The resulting data transmission is handled by the programmer.
Execution is done by calling the object’s run method. The programmer’s run method can operate on the data in any way permitted. Because users would not want their computers executing foreign code without prior knowledge of its functionality, we created a security policy that closely resembles the applet security policy. The only difference is that an applet has certain rights on documents and classes contained in the same or related URL that the applet was loaded from. But, because a downloaded class is not referenced by a URL, the class does not get the same rights as an applet does. A downloaded class’s network ability is restricted to connecting only to the host it came from. It also has no file system access, no access to other threads and no access to the Helper Application itself, just like an applet. With these security restrictions, users should feel safe and willing to allow their computer to be used for unknown computations.
After run returns, the Helper Application calls the object’s sendResults method. sendResults is the application developer’s method that transmits any necessary results over the network.
The Helper Application has the option to get more work from the same server, or to go to another server.
2.3 Communications Among the Components
The Helper Application, Distribution Server, and Computation Server components work together using a common protocol. Figure 1 shows the communications between these components as described above.
Figure 1: Communication Procedure
In order to test our system, we developed two applications that we distributed over the network. The first, Adder, added all the integers in a large range by breaking the range into subranges, and distributing the subranges to different machines to execute. This experience demonstrated that it was straight-forward to implement the required classes to created a downloadable class. This application required only minimal network traffic: two integers to download the arguments, and one integer to return the result.
The second application was a Mandelbrot image generator. Again, we were able to implement the necessary classes to distribute the computation. We used the Mandelbrot image generator to run several tests of the performance of our system.
The first test involved determining if the distributed computation executed more quickly than the corresponding computation running on a single machine. While our tests showed a speed-up effect when running the distributed computation, the effect was difficult to quantify. The machines we had available were of differing speeds, and we determined that the performance on individual machines depended strongly on the efficiency of the Java Virtual Machine implementation available.
We also used the Mandelbrot program to study the effect of network failures on the computation. We simulated network failures by having some of the downloaded applications fail to return a result. The Computation Server, which is responsible for determining the arguments to be used by each Helper Application, is designed to time out if a Helper Application does not return a result before a timer expires. When a time-out occurs, the same set of arguments will be sent to another Helper Application.
In our tests, we simulated a 30% failure rate. The application was still able to complete successfully, although it required about 44% more time than the same application without failures.
The final set of performance tests involved an assessment of the network overhead involved in our system. For a given computation, we varied the number of "chunks" into which we divided the computation. The more chunks, the more network overhead. Figure 2 shows the relation between time to complete the computation and the number of chunks. As expected, increasing the number of chunks increases the computation time. The slope of this line indicates that each additional chuck added 1.33 seconds to the completion time. This result indicates that the size of the computation being distributed should be large enough to justify this additional overhead. Thus our system is suitable for coarse-grain parallel computation.
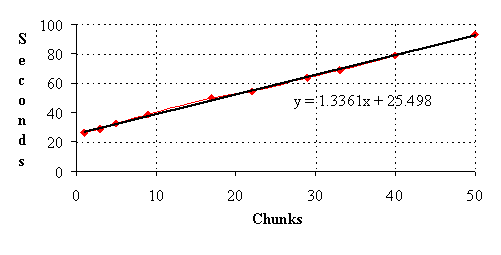
Figure 2: Network Overhead
We have described a project to design and implement a load distribution system written in Java to run over the World Wide Web. We implemented the framework of the system: the Helper Application, the Distribution Server, and the Computation Server. A programmer wishing to prepare an application for execution using our system needs to create a Java class, following our specifications, to carry out the computation. A user willing to help by executing part of the computation needs only to start the Helper Application, which will automatically detect when the computer is idle and locate a computation. The Helper Application downloads a Java class to perform the computation, downloads the arguments to use, executes the computation, and returns the results. A strong security model is built into the Helper Application, so that users can be confident that they will not download computations that will harm their systems. We have shown that our system is practical, and have performed an analysis of the overhead it requires.
In the course of our work on this project, we have identified some opportunities for extensions or improvements which could make the system more useful in the future. One improvement would be to make a distributable applet, so that a user could download a computation to perform by visiting a Web site, without the need to be running a Helper Application. Other improvements focus on security and authentication, so that a Computation Server could authenticate the identity of a host returning results to it, and that the results being returned were correct.
To make our load distribution system more accessible to users, the Helper Application could be built into widely-available Web browsers. If users chose to activate this feature of the Web browser, their computer would automatically download and execute computations. This scenario would lead to an enormous number of machines on the Internet available to support parallel computations, and make use of the vast computational power of idle computers on the Internet.
To provide an incentive to users to participate, a micropayment system could be used. Micropayment systems, such as the Millicent system developed by Digital Equipment Corporation [4], have been proposed as a way of collecting small payments for access to Web resources. These same micropayment systems could be used to pay users a small amount for allowing their system to be used to download and execute distributed computations. Thus users could use the time when their systems would otherwise be idle to earn credits to be used later for access to Web resources. This could provide sufficient incentive for large numbers of users to make their systems available for distributed computations.
References