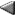
|

|
Data Classification is a crucial task to perform in the visualization process, as the type and structure of the data define the set of graphical mappings that can be performed on that data.
When we speak of different data types, we imply an underlying nxp table, where we store n data points (rows), each with p variables (columns).
| First Name | Last Name | SS# | Sex | Age (years) | Height (inches) | Weight (pounds) | Eye Color |
| Richard | Resnick | 111-22-3434 | male | 25 | 64 | 148 | green |
| Meghan | Lane | 412-19-0000 | female | 22 | 61 | 112 | blue |
| Matt | Ward | 589-03-1234 | male | certainly < 50 | 70 | 160 | blue |
| Steve | Segunchuk | 123-45-6789 | male | 27 | 74 | 155 | blue |
| Sudhir | Kaushik | n/a | male | 22 | 68.5 | 95 | brown |
We are primarily concerned with the type of each variable (column) in the table.
|
|
|