The goal of the research is to devise an efficient and accurate model of the human face and to develop a notational system to encode actions. This notation should be rich enough to make computer recognition possible.
It seems to be very convenient to have a separate notation for body and action representation:
- action-based notation
- This high-level notation is used to describe which actions should be performed. Several systems have been examined for features such as completeness and adaptibility to computer:
- Labanotation is used primarly for describing dance movements, so there is little or no support for facial expressions.
- Sutton-notation is more pictorially based. It does support facial expressions.
- Birdwhistell proposes a large vocabulary of pictorial symbols for describing the actions of both the body and the face.
- The Facial Action Coding System FACS is not graphically-oriented. It describes a set of all possible basic actions performable by the face. Each action is called an Action Unit (AU). An AU is a basic action in the sense that is cannot be broken up into smaller actions. Each action is caused by a minimal number of muscles and is therefore closely connected to the anatomy of the face.
- structure-based notation
- This low-level notation is used to describe the physical model of the face. The high-level actions are decomposed into lower-level structures in order to produce a simulation of the face. Obviously, this notation should be well-chosen since it is the most important part of the simulation. Three known techniques are:
- A simple 2D surface patch technique breaks up to head in small patches of skin. A facial action consist of warping a subset of these patches.
- Parke introduced a parameteric approach to define the face and its actions. This approach has produced some very impressive results. Some subtle interactions of the face do require larger and larger sets of parameters to be manipulated. Since all parametes have to be hardcoded (their existence, not their values), the systems loses some generality.
- A last representation involves a complete low-level simulation of the face. This model consist
of three levels:
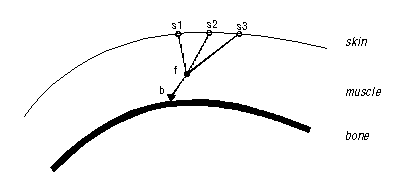
- the bone
- the muscles
- the skin
- action-based notation
Given the two separate notations, the authors propose a system that recognizes facial
actions on a given face (using a camera) and simulate that face:

Both the high-level and the low-level representation (before and after the Internal Model
Manipulator) can be used to store the face for further use, modification or reconstruction
on another computer.
Design of the System
The authors have chosen the tension-net as structure-based representation.
They believe it is the most usable (and general) approach since it is a naturally-based
system. The FACS has been chosen as action-based notation as it is very compatible with
the tension-nets.
The FACS - Tension-net approach offers the following features:
- any performable facial action can be simulated
- it is a naturally based system
- there is a close relation between the cause of an action and its simulation
- FACS is face-independent
- the FACS decomposition is unique
- Efficiency of the representation
- the theory is extensible to cover other non-rigid objects
Subprocesses
- Although the camera processor was not yet accomplished, the authors feel that
it is a possible tasks (although not a trival one !). The program should scan the input image
for certain facial features. These features are used to determine the AUs involved in the
facial action. One of the major problems here is that one AU may mask another one (raising an eyebrow
can make the detection of eyelid actions impossible, ...).
- The AU parser takes a list of AUs and finds the muscle contractions for each one.
- The simulator performs the necessary contractions to simulate the expression.
Datastructures
The basic structures used are:
- adjacent 3D-points are connected by an arc. This arc holds information about
the elasticity, ... . If a force is applied to a point, the change in location is
calculated by
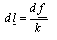 where k is the sum of the spring constants at that point.
where k is the sum of the spring constants at that point.
- a muscle fiber consists of a fiber point, a bone point and one or more
skin points. A force acting on a muscle is applied to the fiber point.

- a muscle typically consists of several fibers. When a muscle contracts, all its fibers
contract in parallel.
- The highest-level structure needed is the AU. This consists of one or more muscles and their
relative magnitudes (these indicate the importance of the muscle for this AU).
Algorithms
When a fiber contracts, a force is applied to its fiber point. The direction of this force
is towards the bone point. The displacement of the fiber point is relative to the elasticity of the flesh. The
force is propagated through all the arcs adjacent to that point.
To simulate a muscle or a set of muscles, the sets of all fibers of all these
muscles is considered.
Animation
When a force can be applied to a muscle as stated above, animation can be achieved simply
by applying a force f/n n times. The animation becomes smoother as n increases,
but at the same time, the computational cost becomes higher, so a tradeoff has to be found.
Problems
Solved
The choice of the representations was backed-up by the fact that the solution of several
expected problems came naturally. The problem of one AU masking the existence of another
(first smile, then raise cheek vs raise cheek: since the cheek is raised during a smile, the second
action of the first case should not have any effect) is handled naturally as a result of the way skin
elasticities are handled. A second problem involving the creation of bulges, wrinkles and
furrows was again handled very will (these are all caused by two forces pushing points
towards each other.
Unsolved
Several problems were not handled at the time of writing:
- muscles following the flow of a bone sheet are not handled well: the muscle should
flow over the bone, not through it !
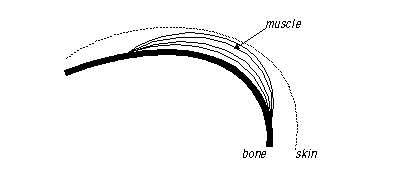
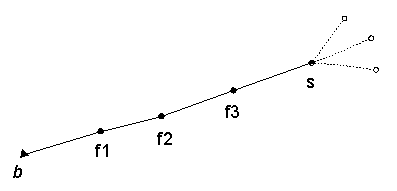
This problem can be solved by altering the representation of the fiber by adding several fiber-points:
- jaw actions are not handles well (yet)
- cheek actions such as sucking and puffing require a complex model of the face
including fluid (air) filled chambers
- totally non-rigid structures (such as the tongue) are not investigated. In the current
model, each fiber always has a bone point.

where k is the sum of the spring constants at that point.
This problem can be solved by altering the representation of the fiber by adding several fiber-points: